
Professional software vendor delivering innovative solutions on the Softono platform. Specialized in both open-source and proprietary software development.
Software by Google

google/cadvisor
  cAdvisor (Container Advisor) provides container users an understanding of the resource usage and performance characteristics of their running containers. It is a running daemon that collects, aggregates, processes, and exports information about running containers. Specifically, for each container it keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage and network statistics. This data is exported by container and machine-wide. cAdvisor has native support for [Docker](https://github.com/docker/docker) containers and should support just about any other container type out of the box. We strive for support across the board so feel free to open an issue if that is not the case. cAdvisor's container abstraction is based on [lmctfy](https://github.com/google/lmctfy)'s so containers are inherently nested hierarchically. #### Quick Start: Running cAdvisor in a Docker Container To quickly tryout cAdvisor on your machine with Docker, we have a Docker image that includes everything you need to get started. You can run a single cAdvisor to monitor the whole machine. Simply run: ``` VERSION=0.55.1 # use the latest release version from https://github.com/google/cadvisor/releases sudo docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ --privileged \ --device=/dev/kmsg \ ghcr.io/google/cadvisor:$VERSION # for versions prior to v0.53.0, use gcr.io/cadvisor/cadvisor instead ``` cAdvisor is now running (in the background) on `http://localhost:8080`. The setup includes directories with Docker state cAdvisor needs to observe. **Note**: If you're running on CentOS, Fedora, or RHEL (or are using LXC), take a look at our [running instructions](docs/running.md). We have detailed [instructions](docs/running.md#standalone) on running cAdvisor standalone outside of Docker. cAdvisor [running options](docs/runtime_options.md) may also be interesting for advanced usecases. If you want to build your own cAdvisor Docker image, see our [deployment](docs/deploy.md) page. For [Kubernetes](https://github.com/kubernetes/kubernetes) users, cAdvisor can be run as a daemonset. See the [instructions](deploy/kubernetes) for how to get started, and for how to [kustomize](https://github.com/kubernetes-sigs/kustomize#kustomize) it to fit your needs. ## Building and Testing See the more detailed instructions in the [build page](docs/development/build.md). This includes instructions for building and deploying the cAdvisor Docker image. ## Exporting stats cAdvisor supports exporting stats to various storage plugins. See the [documentation](docs/storage/README.md) for more details and examples. ## Web UI cAdvisor exposes a web UI at its port: `http://<hostname>:<port>/` See the [documentation](docs/web.md) for more details. ## Remote REST API & Clients cAdvisor exposes its raw and processed stats via a versioned remote REST API. See the API's [documentation](docs/api.md) for more information. There is also an official Go client implementation in the [client](client/) directory. See the [documentation](docs/clients.md) for more information. ## Roadmap cAdvisor aims to improve the resource usage and performance characteristics of running containers. Today, we gather and expose this information to users. In our roadmap: - Advise on the performance of a container (e.g.: when it is being negatively affected by another, when it is not receiving the resources it requires, etc). - Auto-tune the performance of the container based on previous advise. - Provide usage prediction to cluster schedulers and orchestration layers. ## Community Contributions, questions, and comments are all welcomed and encouraged! cAdvisor developers hang out on [Slack](https://kubernetes.slack.com) in the #sig-node channel (get an invitation [here](http://slack.kubernetes.io/)). We also have [discuss.kubernetes.io](https://discuss.kubernetes.io/). Please reach out and get involved in the project, we're actively looking for more contributors to bring on board! ### Core Team * [@bobbypage, Google](https://github.com/bobbypage) * [@iwankgb, Independent](https://github.com/iwankgb) * [@creatone, Independent](https://github.com/creatone) * [@dims, VMWare](https://github.com/dims) * [@mrunalp, RedHat](https://github.com/mrunalp) ### Frequent Collaborators * [@haircommander, RedHat](https://github.com/haircommander) ### Emeritus * [@dashpole, Google](https://github.com/dashpole) * [@dchen1107, Google](https://github.com/dchen1107) * [@derekwaynecarr, RedHat](https://github.com/derekwaynecarr)
google/leveldb
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values. > **This repository is receiving very limited maintenance. We will only review the following types of changes.** > > * Fixes for critical bugs, such as data loss or memory corruption > * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update [](https://github.com/google/leveldb/actions/workflows/build.yml) Authors: Sanjay Ghemawat ([email protected]) and Jeff Dean ([email protected]) # Features * Keys and values are arbitrary byte arrays. * Data is stored sorted by key. * Callers can provide a custom comparison function to override the sort order. * The basic operations are `Put(key,value)`, `Get(key)`, `Delete(key)`. * Multiple changes can be made in one atomic batch. * Users can create a transient snapshot to get a consistent view of data. * Forward and backward iteration is supported over the data. * Data is automatically compressed using the [Snappy compression library](https://google.github.io/snappy/), but [Zstd compression](https://facebook.github.io/zstd/) is also supported. * External activity (file system operations etc.) is relayed through a virtual interface so users can customize the operating system interactions. # Documentation [LevelDB library documentation](https://github.com/google/leveldb/blob/main/doc/index.md) is online and bundled with the source code. # Limitations * This is not a SQL database. It does not have a relational data model, it does not support SQL queries, and it has no support for indexes. * Only a single process (possibly multi-threaded) can access a particular database at a time. * There is no client-server support builtin to the library. An application that needs such support will have to wrap their own server around the library. # Getting the Source ```bash git clone --recurse-submodules https://github.com/google/leveldb.git ``` # Building This project supports [CMake](https://cmake.org/) out of the box. ### Build for POSIX Quick start: ```bash mkdir -p build && cd build cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build . ``` ### Building for Windows First generate the Visual Studio 2017 project/solution files: ```cmd mkdir build cd build cmake -G "Visual Studio 15" .. ``` The default default will build for x86. For 64-bit run: ```cmd cmake -G "Visual Studio 15 Win64" .. ``` To compile the Windows solution from the command-line: ```cmd devenv /build Debug leveldb.sln ``` or open leveldb.sln in Visual Studio and build from within. Please see the CMake documentation and `CMakeLists.txt` for more advanced usage. # Contributing to the leveldb Project > **This repository is receiving very limited maintenance. We will only review the following types of changes.** > > * Bug fixes > * Changes absolutely needed by internally supported leveldb clients. These typically fix breakage introduced by a language/standard library/OS update The leveldb project welcomes contributions. leveldb's primary goal is to be a reliable and fast key/value store. Changes that are in line with the features/limitations outlined above, and meet the requirements below, will be considered. Contribution requirements: 1. **Tested platforms only**. We _generally_ will only accept changes for platforms that are compiled and tested. This means POSIX (for Linux and macOS) or Windows. Very small changes will sometimes be accepted, but consider that more of an exception than the rule. 2. **Stable API**. We strive very hard to maintain a stable API. Changes that require changes for projects using leveldb _might_ be rejected without sufficient benefit to the project. 3. **Tests**: All changes must be accompanied by a new (or changed) test, or a sufficient explanation as to why a new (or changed) test is not required. 4. **Consistent Style**: This project conforms to the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html). To ensure your changes are properly formatted please run: ``` clang-format -i --style=file <file> ``` We are unlikely to accept contributions to the build configuration files, such as `CMakeLists.txt`. We are focused on maintaining a build configuration that allows us to test that the project works in a few supported configurations inside Google. We are not currently interested in supporting other requirements, such as different operating systems, compilers, or build systems. ## Submitting a Pull Request Before any pull request will be accepted the author must first sign a Contributor License Agreement (CLA) at https://cla.developers.google.com/. In order to keep the commit timeline linear [squash](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History#Squashing-Commits) your changes down to a single commit and [rebase](https://git-scm.com/docs/git-rebase) on google/leveldb/main. This keeps the commit timeline linear and more easily sync'ed with the internal repository at Google. More information at GitHub's [About Git rebase](https://help.github.com/articles/about-git-rebase/) page. # Performance Here is a performance report (with explanations) from the run of the included db_bench program. The results are somewhat noisy, but should be enough to get a ballpark performance estimate. ## Setup We use a database with a million entries. Each entry has a 16 byte key, and a 100 byte value. Values used by the benchmark compress to about half their original size. LevelDB: version 1.1 Date: Sun May 1 12:11:26 2011 CPU: 4 x Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz CPUCache: 4096 KB Keys: 16 bytes each Values: 100 bytes each (50 bytes after compression) Entries: 1000000 Raw Size: 110.6 MB (estimated) File Size: 62.9 MB (estimated) ## Write performance The "fill" benchmarks create a brand new database, in either sequential, or random order. The "fillsync" benchmark flushes data from the operating system to the disk after every operation; the other write operations leave the data sitting in the operating system buffer cache for a while. The "overwrite" benchmark does random writes that update existing keys in the database. fillseq : 1.765 micros/op; 62.7 MB/s fillsync : 268.409 micros/op; 0.4 MB/s (10000 ops) fillrandom : 2.460 micros/op; 45.0 MB/s overwrite : 2.380 micros/op; 46.5 MB/s Each "op" above corresponds to a write of a single key/value pair. I.e., a random write benchmark goes at approximately 400,000 writes per second. Each "fillsync" operation costs much less (0.3 millisecond) than a disk seek (typically 10 milliseconds). We suspect that this is because the hard disk itself is buffering the update in its memory and responding before the data has been written to the platter. This may or may not be safe based on whether or not the hard disk has enough power to save its memory in the event of a power failure. ## Read performance We list the performance of reading sequentially in both the forward and reverse direction, and also the performance of a random lookup. Note that the database created by the benchmark is quite small. Therefore the report characterizes the performance of leveldb when the working set fits in memory. The cost of reading a piece of data that is not present in the operating system buffer cache will be dominated by the one or two disk seeks needed to fetch the data from disk. Write performance will be mostly unaffected by whether or not the working set fits in memory. readrandom : 16.677 micros/op; (approximately 60,000 reads per second) readseq : 0.476 micros/op; 232.3 MB/s readreverse : 0.724 micros/op; 152.9 MB/s LevelDB compacts its underlying storage data in the background to improve read performance. The results listed above were done immediately after a lot of random writes. The results after compactions (which are usually triggered automatically) are better. readrandom : 11.602 micros/op; (approximately 85,000 reads per second) readseq : 0.423 micros/op; 261.8 MB/s readreverse : 0.663 micros/op; 166.9 MB/s Some of the high cost of reads comes from repeated decompression of blocks read from disk. If we supply enough cache to the leveldb so it can hold the uncompressed blocks in memory, the read performance improves again: readrandom : 9.775 micros/op; (approximately 100,000 reads per second before compaction) readrandom : 5.215 micros/op; (approximately 190,000 reads per second after compaction) ## Repository contents See [doc/index.md](doc/index.md) for more explanation. See [doc/impl.md](doc/impl.md) for a brief overview of the implementation. The public interface is in include/leveldb/*.h. Callers should not include or rely on the details of any other header files in this package. Those internal APIs may be changed without warning. Guide to header files: * **include/leveldb/db.h**: Main interface to the DB: Start here. * **include/leveldb/options.h**: Control over the behavior of an entire database, and also control over the behavior of individual reads and writes. * **include/leveldb/comparator.h**: Abstraction for user-specified comparison function. If you want just bytewise comparison of keys, you can use the default comparator, but clients can write their own comparator implementations if they want custom ordering (e.g. to handle different character encodings, etc.). * **include/leveldb/iterator.h**: Interface for iterating over data. You can get an iterator from a DB object. * **include/leveldb/write_batch.h**: Interface for atomically applying multiple updates to a database. * **include/leveldb/slice.h**: A simple module for maintaining a pointer and a length into some other byte array. * **include/leveldb/status.h**: Status is returned from many of the public interfaces and is used to report success and various kinds of errors. * **include/leveldb/env.h**: Abstraction of the OS environment. A posix implementation of this interface is in util/env_posix.cc. * **include/leveldb/table.h, include/leveldb/table_builder.h**: Lower-level modules that most clients probably won't use directly.
langextract
<p align="center"> <a href="https://github.com/google/langextract"> <img src="https://raw.githubusercontent.com/google/langextract/main/docs/_static/logo.svg" alt="LangExtract Logo" width="128" /> </a> </p> # LangExtract [](https://pypi.org/project/langextract/) [](https://github.com/google/langextract)  [](https://doi.org/10.5281/zenodo.17015089) ## Table of Contents - [Introduction](#introduction) - [Why LangExtract?](#why-langextract) - [Quick Start](#quick-start) - [Installation](#installation) - [API Key Setup for Cloud Models](#api-key-setup-for-cloud-models) - [Adding Custom Model Providers](#adding-custom-model-providers) - [Using OpenAI Models](#using-openai-models) - [Using Local LLMs with Ollama](#using-local-llms-with-ollama) - [More Examples](#more-examples) - [*Romeo and Juliet* Full Text Extraction](#romeo-and-juliet-full-text-extraction) - [Medication Extraction](#medication-extraction) - [Radiology Report Structuring: RadExtract](#radiology-report-structuring-radextract) - [Community Providers](#community-providers) - [Contributing](#contributing) - [Testing](#testing) - [Disclaimer](#disclaimer) ## Introduction LangExtract is a Python library that uses LLMs to extract structured information from unstructured text documents based on user-defined instructions. It processes materials such as clinical notes or reports, identifying and organizing key details while ensuring the extracted data corresponds to the source text. ## Why LangExtract? 1. **Precise Source Grounding:** Maps every extraction to its exact location in the source text, enabling visual highlighting for easy traceability and verification. 2. **Reliable Structured Outputs:** Enforces a consistent output schema based on your few-shot examples, leveraging controlled generation in supported models like Gemini to guarantee robust, structured results. 3. **Optimized for Long Documents:** Overcomes the "needle-in-a-haystack" challenge of large document extraction by using an optimized strategy of text chunking, parallel processing, and multiple passes for higher recall. 4. **Interactive Visualization:** Instantly generates a self-contained, interactive HTML file to visualize and review thousands of extracted entities in their original context. 5. **Flexible LLM Support:** Supports your preferred models, from cloud-based LLMs like the Google Gemini family to local open-source models via the built-in Ollama interface. 6. **Adaptable to Any Domain:** Define extraction tasks for any domain using just a few examples. LangExtract adapts to your needs without requiring any model fine-tuning. 7. **Leverages LLM World Knowledge:** Utilize precise prompt wording and few-shot examples to influence how the extraction task may utilize LLM knowledge. The accuracy of any inferred information and its adherence to the task specification are contingent upon the selected LLM, the complexity of the task, the clarity of the prompt instructions, and the nature of the prompt examples. ## Quick Start > **Note:** Using cloud-hosted models like Gemini requires an API key. See the [API Key Setup](#api-key-setup-for-cloud-models) section for instructions on how to get and configure your key. Extract structured information with just a few lines of code. ### 1. Define Your Extraction Task First, create a prompt that clearly describes what you want to extract. Then, provide a high-quality example to guide the model. ```python import langextract as lx import textwrap # 1. Define the prompt and extraction rules prompt = textwrap.dedent("""\ Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities. Provide meaningful attributes for each entity to add context.""") # 2. Provide a high-quality example to guide the model examples = [ lx.data.ExampleData( text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.", extractions=[ lx.data.Extraction( extraction_class="character", extraction_text="ROMEO", attributes={"emotional_state": "wonder"} ), lx.data.Extraction( extraction_class="emotion", extraction_text="But soft!", attributes={"feeling": "gentle awe"} ), lx.data.Extraction( extraction_class="relationship", extraction_text="Juliet is the sun", attributes={"type": "metaphor"} ), ] ) ] ``` > **Note:** Examples drive model behavior. Each `extraction_text` should ideally be verbatim from the example's `text` (no paraphrasing), listed in order of appearance. LangExtract raises `Prompt alignment` warnings by default if examples don't follow this pattern—resolve these for best results. > > **Grounding:** LLMs may occasionally extract content from few-shot examples rather than the input text. LangExtract automatically detects this: extractions that cannot be located in the source text will have `char_interval = None`. Filter these out with `[e for e in result.extractions if e.char_interval]` to keep only grounded results. ### 2. Run the Extraction Provide your input text and the prompt materials to the `lx.extract` function. ```python # The input text to be processed input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo" # Run the extraction result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, model_id="gemini-3.5-flash", ) ``` > **Model Selection**: `gemini-3.5-flash` is the recommended default, offering strong extraction quality for LangExtract's schema-constrained workflows. For high-volume or cost-sensitive workloads, consider the current stable Flash-Lite model, `gemini-3.1-flash-lite`; for highly complex tasks requiring deeper reasoning, evaluate a current Gemini Pro model from the official model documentation. For large-scale or production use, a paid Gemini tier is suggested to increase throughput and avoid rate limits. See the [rate-limit documentation](https://ai.google.dev/gemini-api/docs/rate-limits#usage-tiers) for details. > > **Model Lifecycle**: Note that Gemini models have a lifecycle with defined retirement dates. Users should consult the [official model version documentation](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/model-versions) to stay informed about the latest stable and legacy versions. ### 3. Visualize the Results The extractions can be saved to a `.jsonl` file, a popular format for working with language model data. LangExtract can then generate an interactive HTML visualization from this file to review the entities in context. ```python # Save the results to a JSONL file lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".") # Generate the visualization from the file html_content = lx.visualize("extraction_results.jsonl") with open("visualization.html", "w") as f: if hasattr(html_content, 'data'): f.write(html_content.data) # For Jupyter/Colab else: f.write(html_content) ``` This creates an animated and interactive HTML file: 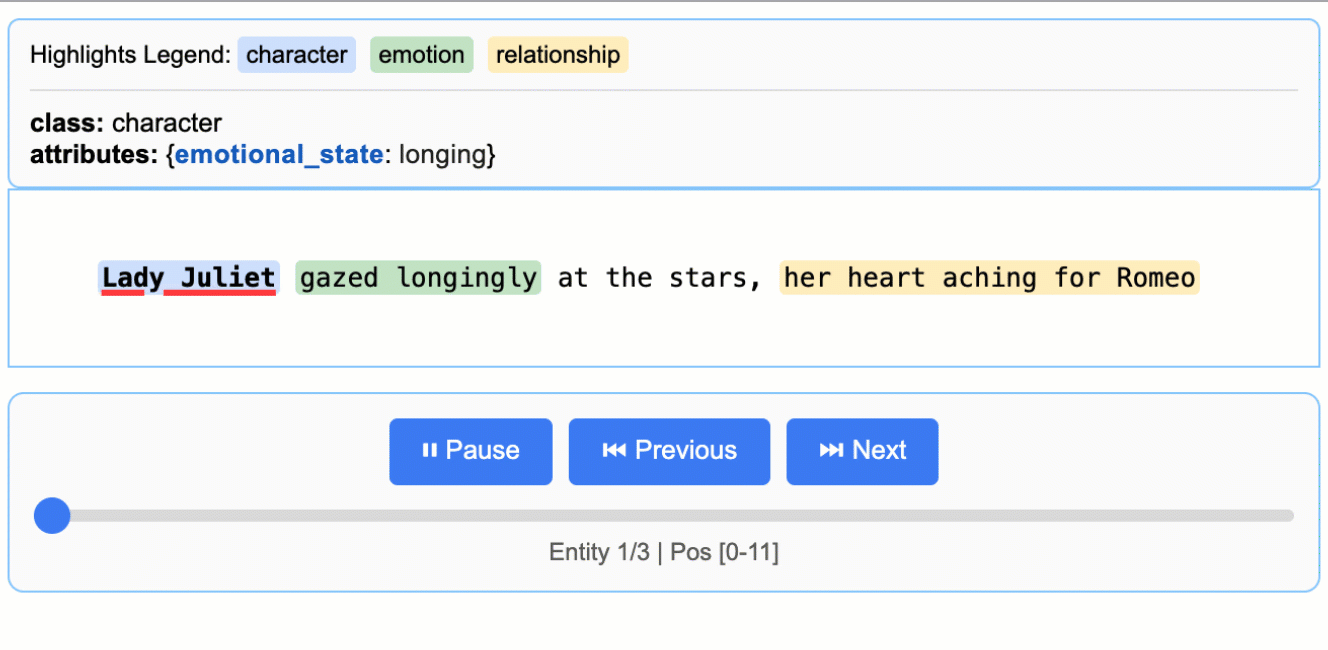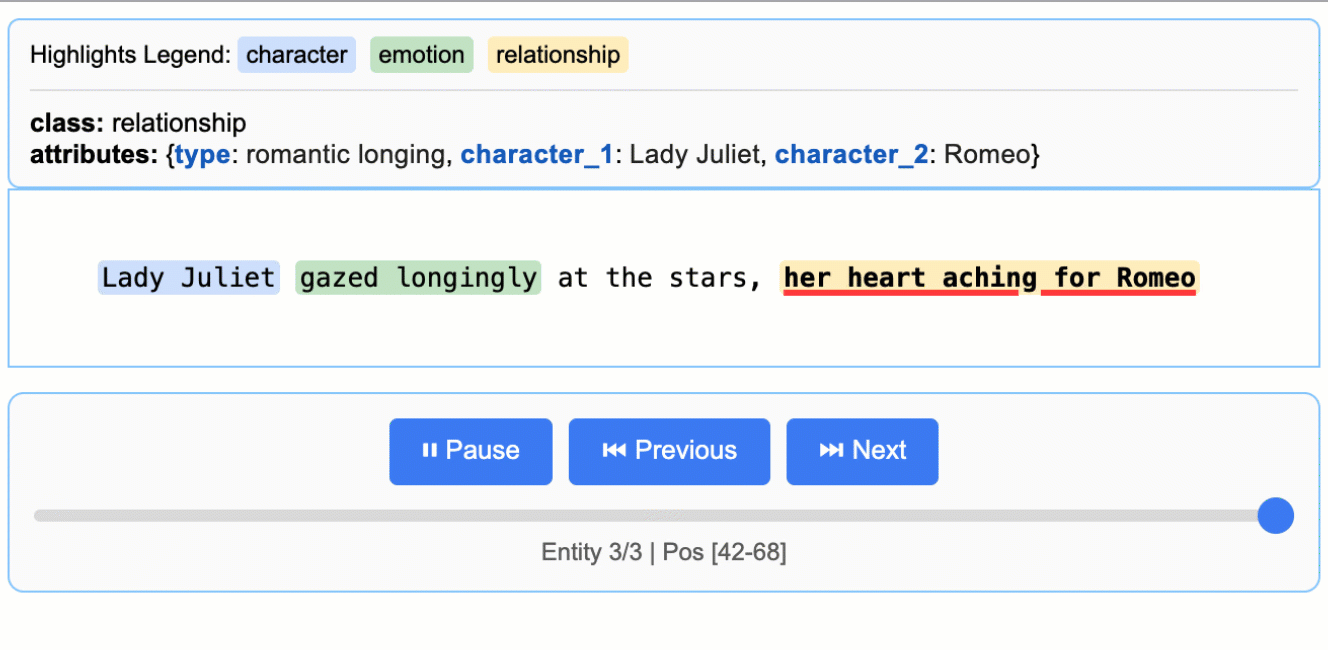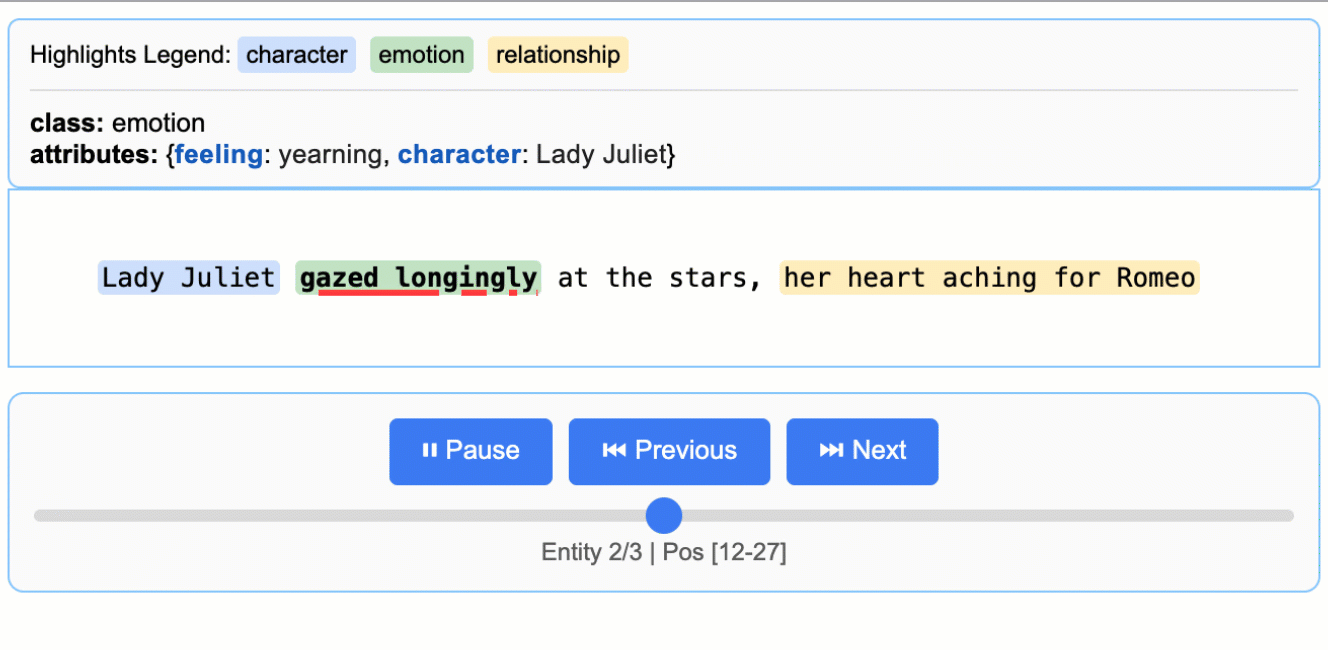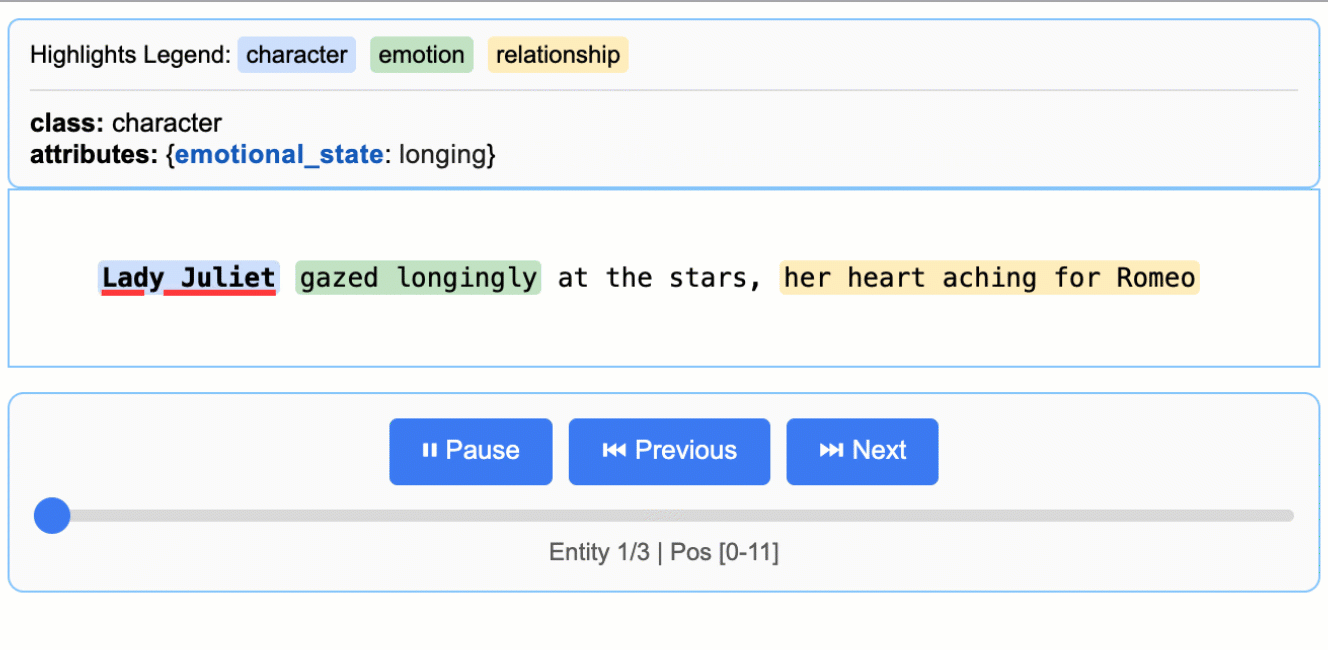 > **Note on LLM Knowledge Utilization:** This example demonstrates extractions that stay close to the text evidence - extracting "longing" for Lady Juliet's emotional state and identifying "yearning" from "gazed longingly at the stars." The task could be modified to generate attributes that draw more heavily from the LLM's world knowledge (e.g., adding `"identity": "Capulet family daughter"` or `"literary_context": "tragic heroine"`). The balance between text-evidence and knowledge-inference is controlled by your prompt instructions and example attributes. ### Scaling to Longer Documents For larger texts, you can process entire documents directly from URLs with parallel processing and enhanced sensitivity: ```python # Process Romeo & Juliet directly from Project Gutenberg result = lx.extract( text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt", prompt_description=prompt, examples=examples, model_id="gemini-3.5-flash", extraction_passes=3, # Improves recall through multiple passes max_workers=20, # Parallel processing for speed max_char_buffer=1000 # Smaller contexts for better accuracy ) ``` This approach can extract hundreds of entities from full novels while maintaining high accuracy. The interactive visualization seamlessly handles large result sets, making it easy to explore hundreds of entities from the output JSONL file. **[See the full *Romeo and Juliet* extraction example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)** for detailed results and performance insights. ### Vertex AI Batch Processing Save costs on large-scale tasks by enabling Vertex AI Batch API: `language_model_params={"vertexai": True, "batch": {"enabled": True}}`. See an example of the Vertex AI Batch API usage in [this example](docs/examples/batch_api_example.md). ## Installation ### From PyPI ```bash pip install langextract ``` *Recommended for most users. For isolated environments, consider using a virtual environment:* ```bash python -m venv langextract_env source langextract_env/bin/activate # On Windows: langextract_env\Scripts\activate pip install langextract ``` ### From Source LangExtract uses modern Python packaging with `pyproject.toml` for dependency management: *Installing with `-e` puts the package in development mode, allowing you to modify the code without reinstalling.* ```bash git clone https://github.com/google/langextract.git cd langextract # For basic installation: pip install -e . # For development (includes linting tools): pip install -e ".[dev]" # For testing (includes pytest): pip install -e ".[test]" ``` ### Docker ```bash docker build -t langextract . docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py ``` ## API Key Setup for Cloud Models When using LangExtract with cloud-hosted models (like Gemini or OpenAI), you'll need to set up an API key. On-device models don't require an API key. For developers using local LLMs, LangExtract offers built-in support for Ollama and can be extended to other third-party APIs by updating the inference endpoints. ### API Key Sources Get API keys from: * [AI Studio](https://aistudio.google.com/app/apikey) for Gemini models * [Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/sdks/overview) for enterprise use * [OpenAI Platform](https://platform.openai.com/api-keys) for OpenAI models ### Setting up API key in your environment **Option 1: Environment Variable** ```bash export LANGEXTRACT_API_KEY="your-api-key-here" ``` **Option 2: .env File (Recommended)** Add your API key to a `.env` file: ```bash # Add API key to .env file cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOF # Keep your API key secure echo '.env' >> .gitignore ``` In your Python code: ```python import langextract as lx result = lx.extract( text_or_documents=input_text, prompt_description="Extract information...", examples=[...], model_id="gemini-3.5-flash" ) ``` **Option 3: Direct API Key (Not Recommended for Production)** You can also provide the API key directly in your code, though this is not recommended for production use: ```python result = lx.extract( text_or_documents=input_text, prompt_description="Extract information...", examples=[...], model_id="gemini-3.5-flash", api_key="your-api-key-here" # Only use this for testing/development ) ``` **Option 4: Vertex AI (Service Accounts)** Use [Vertex AI](https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform) for authentication with service accounts: ```python result = lx.extract( text_or_documents=input_text, prompt_description="Extract information...", examples=[...], model_id="gemini-3.5-flash", language_model_params={ "vertexai": True, "project": "your-project-id", "location": "global" # or regional endpoint } ) ``` ## Adding Custom Model Providers LangExtract supports custom LLM providers via a lightweight plugin system. You can add support for new models without changing core code. - Add new model support independently of the core library - Distribute your provider as a separate Python package - Keep custom dependencies isolated - Override or extend built-in providers via priority-based resolution See the detailed guide in [Provider System Documentation](langextract/providers/README.md) to learn how to: - Register a provider with `@router.register(...)` from `langextract.providers` - Publish an entry point for discovery - Optionally provide a schema with `get_schema_class()` for structured output - Integrate with the factory via `create_model(...)` ## Using OpenAI Models LangExtract supports OpenAI models (requires optional dependency: `pip install langextract[openai]`): ```python import langextract as lx # OPENAI_API_KEY in the environment is picked up automatically; pass # api_key=... explicitly only if you need to override it. result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, model_id="gpt-4o", # Automatically selects OpenAI provider ) ``` The OpenAI provider uses JSON mode and auto-determines fence and schema behavior — leave `fence_output` and `use_schema_constraints` unset. For large, non-latency-sensitive OpenAI workloads, enable the OpenAI Batch API with `language_model_params`. Batch mode is opt-in and falls back to realtime calls when the prompt count is below the configured threshold. ```python result = lx.extract( text_or_documents=documents, prompt_description=prompt, examples=examples, model_id="gpt-4o-mini", language_model_params={ "batch": { "enabled": True, "threshold": 50, "poll_interval": 10, } }, ) ``` For OpenAI-compatible endpoints or non-GPT model IDs (which skip auto-routing), use `ModelConfig` with an explicit provider: ```python from langextract.factory import ModelConfig result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, config=ModelConfig( model_id="my-openai-compatible-model", provider="openai", provider_kwargs={"api_key": "sk-...", "base_url": "https://..."}, ), ) ``` ## Using Local LLMs with Ollama LangExtract supports local inference using Ollama, allowing you to run models without API keys: ```python import langextract as lx result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, model_id="gemma2:2b", # Automatically selects Ollama provider model_url="http://localhost:11434", ) ``` The Ollama provider exposes `FormatModeSchema` for JSON mode. Leave `fence_output` and `use_schema_constraints` unset so the factory auto-configures from the provider's schema. **Quick setup:** Install Ollama from [ollama.com](https://ollama.com/), run `ollama pull gemma2:2b`, then `ollama serve`. For detailed installation, Docker setup, and examples, see [`examples/ollama/`](examples/ollama/). ## More Examples Additional examples of LangExtract in action: ### *Romeo and Juliet* Full Text Extraction LangExtract can process complete documents directly from URLs. This example demonstrates extraction from the full text of *Romeo and Juliet* from Project Gutenberg (147,843 characters), showing parallel processing, sequential extraction passes, and performance optimization for long document processing. **[View *Romeo and Juliet* Full Text Example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)** ### Medication Extraction > **Disclaimer:** This demonstration is for illustrative purposes of LangExtract's baseline capability only. It does not represent a finished or approved product, is not intended to diagnose or suggest treatment of any disease or condition, and should not be used for medical advice. LangExtract excels at extracting structured medical information from clinical text. These examples demonstrate both basic entity recognition (medication names, dosages, routes) and relationship extraction (connecting medications to their attributes), showing LangExtract's effectiveness for healthcare applications. **[View Medication Examples →](https://github.com/google/langextract/blob/main/docs/examples/medication_examples.md)** ### Radiology Report Structuring: RadExtract Explore RadExtract, a live interactive demo on HuggingFace Spaces that shows how LangExtract can automatically structure radiology reports. Try it directly in your browser with no setup required. **[View RadExtract Demo →](https://huggingface.co/spaces/google/radextract)** ## Community Providers Extend LangExtract with custom model providers! Check out our [Community Provider Plugins](COMMUNITY_PROVIDERS.md) registry to discover providers created by the community or add your own. For detailed instructions on creating a provider plugin, see the [Custom Provider Plugin Example](examples/custom_provider_plugin/). ## Contributing Contributions are welcome! See [CONTRIBUTING.md](https://github.com/google/langextract/blob/main/CONTRIBUTING.md) to get started with development, testing, and pull requests. You must sign a [Contributor License Agreement](https://cla.developers.google.com/about) before submitting patches. ## Testing To run tests locally from the source: ```bash # Clone the repository git clone https://github.com/google/langextract.git cd langextract # Install with test dependencies pip install -e ".[test]" # Run all tests pytest tests ``` Or reproduce the full CI matrix locally with tox: ```bash tox # runs pylint + pytest on Python 3.10 and 3.11 ``` ### Ollama Integration Testing If you have Ollama installed locally, you can run integration tests: ```bash # Test Ollama integration (requires Ollama running with gemma2:2b model) tox -e ollama-integration ``` This test will automatically detect if Ollama is available and run real inference tests. ## Development ### Code Formatting This project uses automated formatting tools to maintain consistent code style: ```bash # Auto-format all code ./autoformat.sh # Or run formatters separately isort langextract tests --profile google --line-length 80 pyink langextract tests --config pyproject.toml ``` ### Pre-commit Hooks For automatic formatting checks: ```bash pre-commit install # One-time setup pre-commit run --all-files # Manual run ``` ### Linting Run linting before submitting PRs: ```bash pylint --rcfile=.pylintrc langextract tests ``` See [CONTRIBUTING.md](CONTRIBUTING.md) for full development guidelines. ## Disclaimer This is not an officially supported Google product. If you use LangExtract in production or publications, please cite accordingly and acknowledge usage. Use is subject to the [Apache 2.0 License](https://github.com/google/langextract/blob/main/LICENSE). For health-related applications, use of LangExtract is also subject to the [Health AI Developer Foundations Terms of Use](https://developers.google.com/health-ai-developer-foundations/terms). --- **Happy Extracting!**
adk-python
# Agent Development Kit (ADK) 2.0 [](LICENSE) <h2 align="center"> <img src="https://raw.githubusercontent.com/google/adk-python/main/assets/agent-development-kit.png" width="256"/> </h2> <h3 align="center"> An open-source, code-first Python framework for building, evaluating, and deploying sophisticated AI agents with flexibility and control. </h3> <h3 align="center"> Important Links: <a href="https://google.github.io/adk-docs/">Docs</a>, <a href="https://github.com/google/adk-samples">Samples</a> & <a href="https://github.com/google/adk-web">ADK Web</a>. </h3> ______________________________________________________________________ > **⚠️ BREAKING CHANGES FROM 1.x** > > This release includes breaking changes to the agent API, event model, and > session schema. **Sessions generated by ADK 2.0 are readable by ADK 1.28+ > (extra fields will be ignored), but are incompatible with older 1.x versions.** ______________________________________________________________________ ## 🔥 What's New in 2.0 - **Workflow Runtime**: A graph-based execution engine for composing deterministic execution flows for agentic apps, with support for routing, fan-out/fan-in, loops, retry, state management, dynamic nodes, human-in-the-loop, and nested workflows. - **Task API**: Structured agent-to-agent delegation with multi-turn task mode, single-turn controlled output, mixed delegation patterns, human-in-the-loop, and task agents as workflow nodes. ## 🚀 Installation ```bash pip install google-adk ``` **Requirements:** Python 3.11+. To install optional integrations, you can use the following command: ```bash pip install "google-adk[extensions]" ``` The release cadence is roughly bi-weekly. ## Quick Start ### Agent ```python from google.adk import Agent root_agent = Agent( name="greeting_agent", model="gemini-2.5-flash", instruction="You are a helpful assistant. Greet the user warmly.", ) ``` ### Workflow ```python from google.adk import Agent, Workflow generate_fruit_agent = Agent( name="generate_fruit_agent", instruction="Return the name of a random fruit. Return only the name.", ) generate_benefit_agent = Agent( name="generate_benefit_agent", instruction="Tell me a health benefit about the specified fruit.", ) root_agent = Workflow( name="root_agent", edges=[("START", generate_fruit_agent, generate_benefit_agent)], ) ``` ### Run Locally ```bash # Interactive CLI adk run path/to/my_agent # Web UI (supports multi-agent directories or pointing directly to a single agent folder) adk web path/to/agents_dir ``` ## 📚 Documentation - **Getting Started**: https://google.github.io/adk-docs/ - **Samples**: See `contributing/workflow_samples/` and `contributing/task_samples/` for workflow and task API examples. ## 🤝 Contributing See [CONTRIBUTING.md](CONTRIBUTING.md) for details. ## 📄 License This project is licensed under the Apache 2.0 License — see the [LICENSE](LICENSE) file for details.
adk-go
# Agent Development Kit (ADK) for Go [](LICENSE) [](https://pkg.go.dev/google.golang.org/adk) [](https://github.com/google/adk-go/actions/workflows/nightly.yml) [](https://www.reddit.com/r/agentdevelopmentkit/) [](https://codewiki.google/github.com/google/adk-go) <html> <h2 align="center"> <img src="https://raw.githubusercontent.com/google/adk-python/main/assets/agent-development-kit.png" width="256"/> </h2> <h3 align="center"> An open-source, code-first Go toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control. </h3> <h3 align="center"> Important Links: <a href="https://google.github.io/adk-docs/">Docs</a> & <a href="https://github.com/google/adk-go/tree/main/examples">Samples</a> & <a href="https://github.com/google/adk-python">Python ADK</a> & <a href="https://github.com/google/adk-java">Java ADK</a> & <a href="https://github.com/google/adk-web">ADK Web</a>. </h3> </html> Agent Development Kit (ADK) is a flexible and modular framework that applies software development principles to AI agent creation. It is designed to simplify building, deploying, and orchestrating agent workflows, from simple tasks to complex systems. While optimized for Gemini, ADK is model-agnostic, deployment-agnostic, and compatible with other frameworks. This Go version of ADK is ideal for developers building cloud-native agent applications, leveraging Go's strengths in concurrency and performance. --- ## ✨ Key Features * **Idiomatic Go:** Designed to feel natural and leverage the power of Go. * **Rich Tool Ecosystem:** Utilize pre-built tools, custom functions, or integrate existing tools to give agents diverse capabilities. * **Code-First Development:** Define agent logic, tools, and orchestration directly in Go for ultimate flexibility, testability, and versioning. * **Modular Multi-Agent Systems:** Design scalable applications by composing multiple specialized agents. * **Deploy Anywhere:** Easily containerize and deploy agents, with strong support for cloud-native environments like Google Cloud Run. ## 🚀 Installation To add ADK Go to your project, run: ```bash go get google.golang.org/adk ``` ## 📄 License This project is licensed under the Apache 2.0 License - see the [LICENSE](LICENSE) file for details. The exception is internal/httprr - see its [LICENSE file](internal/httprr/LICENSE).
magika
# Magika [](https://pypi.python.org/pypi/magika) [](https://npmjs.com/package/magika) [](https://pypi.python.org/pypi/magika) [](https://pypi.python.org/pypi/magika) [](https://pkg.go.dev/github.com/google/magika/go) <!-- [](https://scorecard.dev/viewer/?uri=github.com/google/magika) --> [](https://www.bestpractices.dev/en/projects/8706)  [](https://github.com/google/magika/actions) [](https://pepy.tech/projects/magika) [](https://pepy.tech/projects/magika) Magika is a novel AI-powered file type detection tool that relies on the recent advance of deep learning to provide accurate detection. Under the hood, Magika employs a custom, highly optimized model that only weighs about a few MBs, and enables precise file identification within milliseconds, even when running on a single CPU. Magika has been trained and evaluated on a dataset of ~100M samples across 200+ content types (covering both binary and textual file formats), and it achieves an average ~99% accuracy on our test set. Here is an example of what Magika command line output looks like: <p align="center"> <img src="./assets/magika-screenshot.png" width="600"> </p> Magika is used at scale to help improve Google users' safety by routing Gmail, Drive, and Safe Browsing files to the proper security and content policy scanners, processing hundreds billions samples on a weekly basis. Magika has also been integrated with [VirusTotal](https://www.virustotal.com/) ([example](./assets/magika-vt.png)) and [abuse.ch](https://bazaar.abuse.ch/) ([example](./assets/magika-abusech.png)). For more context you can read our initial [announcement post on Google's OSS blog](https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html), you can consult [Magika's website](https://securityresearch.google/magika/), and you can read more in our [research paper](https://securityresearch.google/magika/additional-resources/research-papers-and-citation/), published at the IEEE/ACM International Conference on Software Engineering (ICSE) 2025. You can try Magika without installing anything by using our [web demo](https://securityresearch.google/magika/demo/magika-demo/), which runs locally in your browser! # Highlights - Available as a command line tool written in Rust, a Python API, and additional bindings for Rust, JavaScript/TypeScript (with an experimental npm package, which powers our [web demo](https://securityresearch.google/magika/demo/magika-demo/)), and GoLang (WIP). - Trained and evaluated on a dataset of ~100M files across [200+ content types](./assets/models/standard_v3_3/README.md). - On our test set, Magika achieves ~99% average precision and recall, outperforming existing approaches -- especially on textual content types. - After the model is loaded (which is a one-off overhead), the inference time is about 5ms per file, even when run on a single CPU. - You can invoke Magika with even thousands of files at the same time. You can also use `-r` for recursively scanning a directory. - Near-constant inference time, independently from the file size; Magika only uses a limited subset of the file's content. - Magika uses a per-content-type threshold system that determines whether to "trust" the prediction for the model, or whether to return a generic label, such as "Generic text document" or "Unknown binary data". - The tolerance to errors can be controlled via different prediction modes, such as `high-confidence`, `medium-confidence`, and `best-guess`. - The client and the bindings are already open source, and more is coming soon! # Table of Contents 1. [Getting Started](#getting-started) 1. [Installation](#installation) 1. [Quick Start](#quick-start) 1. [Documentation](#documentation) 1. [Security Vulnerabilities](#security-vulnerabilities) 1. [License](#license) 1. [Disclaimer](#disclaimer) # Getting Started ## Installation ### Command Line Tool Magika ships a CLI written in Rust, and can be installed in several ways. Via `magika` python package: ```shell pipx install magika ``` Via brew (macOS / Linux) ```shell brew install magika ``` Via installer script: ```shell curl -LsSf https://securityresearch.google/magika/install.sh | sh ``` or: ```shell powershell -ExecutionPolicy Bypass -c "irm https://securityresearch.google/magika/install.ps1 | iex" ``` Via `magika-cli` Rust package: ```shell cargo install --locked magika-cli ``` ### Python package ```shell pip install magika ``` ### JavaScript package ```shell npm install magika ``` ## Quick Start Here you can find a number of quick examples just to get you started. To learn about Magika's inner workings, see the [Core Concepts](https://securityresearch.google/magika/core-concepts/) section of Magika's website. ### Command Line Tool Examples ```shell % cd tests_data/basic && magika -r * | head asm/code.asm: Assembly (code) batch/simple.bat: DOS batch file (code) c/code.c: C source (code) css/code.css: CSS source (code) csv/magika_test.csv: CSV document (code) dockerfile/Dockerfile: Dockerfile (code) docx/doc.docx: Microsoft Word 2007+ document (document) docx/magika_test.docx: Microsoft Word 2007+ document (document) eml/sample.eml: RFC 822 mail (text) empty/empty_file: Empty file (inode) ``` ```shell % magika ./tests_data/basic/python/code.py --json [ { "path": "./tests_data/basic/python/code.py", "result": { "status": "ok", "value": { "dl": { "description": "Python source", "extensions": [ "py", "pyi" ], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python" }, "output": { "description": "Python source", "extensions": [ "py", "pyi" ], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python" }, "score": 0.996999979019165 } } } ] ``` ```shell % cat tests_data/basic/ini/doc.ini | magika - -: INI configuration file (text) ``` ```shell % magika --help Determines file content types using AI Usage: magika [OPTIONS] [PATH]... Arguments: [PATH]... List of paths to the files to analyze. Use a dash (-) to read from standard input (can only be used once). Options: -r, --recursive Identifies files within directories instead of identifying the directory itself --no-dereference Identifies symbolic links as is instead of identifying their content by following them --colors Prints with colors regardless of terminal support --no-colors Prints without colors regardless of terminal support -s, --output-score Prints the prediction score in addition to the content type -i, --mime-type Prints the MIME type instead of the content type description -l, --label Prints a simple label instead of the content type description --json Prints in JSON format --jsonl Prints in JSONL format --format <CUSTOM> Prints using a custom format (use --help for details). The following placeholders are supported: %p The file path %l The unique label identifying the content type %d The description of the content type %g The group of the content type %m The MIME type of the content type %e Possible file extensions for the content type %s The score of the content type for the file %S The score of the content type for the file in percent %b The model output if overruled (empty otherwise) %% A literal % -h, --help Print help (see a summary with '-h') -V, --version Print version ``` For more examples and documentation about the CLI, see https://crates.io/crates/magika-cli. ### Python Examples ```python >>> from magika import Magika >>> m = Magika() >>> res = m.identify_bytes(b'function log(msg) {console.log(msg);}') >>> print(res.output.label) javascript ``` ```python >>> from magika import Magika >>> m = Magika() >>> res = m.identify_path('./tests_data/basic/ini/doc.ini') >>> print(res.output.label) ini ``` ```python >>> from magika import Magika >>> m = Magika() >>> with open('./tests_data/basic/ini/doc.ini', 'rb') as f: >>> res = m.identify_stream(f) >>> print(res.output.label) ini ``` For more examples and documentation about the Python module, see the [Python `Magika` module](https://securityresearch.google/magika/cli-and-bindings/python/) section. # Documentation Please consult [Magika's website](https://securityresearch.google/magika) for detailed documentation about: - Core Concepts - How Magika works - Models & content types - Prediction modes - Understanding the output - CLI & Bindings (Python module, JavaScript module, ...) - Contributing - FAQ - ... # Security Vulnerabilities Please contact us directly at [email protected]. # License Apache 2.0; see [`LICENSE`](LICENSE) for details. # Disclaimer This project is not an official Google project. It is not supported by Google and Google specifically disclaims all warranties as to its quality, merchantability, or fitness for a particular purpose.
deepvariant
DeepVariant is an analysis pipeline that uses a deep neural network to call genetic variants from next-generation DNA sequencing data.
langfun
<div align="center"> <img src="https://raw.githubusercontent.com/google/langfun/main/docs/_static/logo.svg" width="520px" alt="logo"></img> </div> # Langfun [](https://badge.fury.io/py/langfun) [](https://codecov.io/gh/google/langfun)  [**Installation**](#install) | [**Getting started**](#hello-langfun) | [**Tutorial**](https://colab.research.google.com/github/google/langfun/blob/main/docs/notebooks/langfun101.ipynb) | [**Discord community**](https://discord.gg/U6wPN9R68k) ## Introduction Langfun is a [PyGlove](https://github.com/google/pyglove) powered library that aims to *make language models (LM) fun to work with*. Its central principle is to enable seamless integration between natural language and programming by treating language as functions. Through the introduction of *Object-Oriented Prompting*, Langfun empowers users to prompt LLMs using objects and types, offering enhanced control and simplifying agent development. To unlock the magic of Langfun, you can start with [Langfun 101](https://colab.research.google.com/github/google/langfun/blob/main/docs/notebooks/langfun101.ipynb). Notably, Langfun is compatible with popular LLMs such as Gemini, GPT, Claude, all without the need for additional fine-tuning. ## Why Langfun? Langfun is *powerful and scalable*: * Seamless integration between natural language and computer programs. * Modular prompts, which allows a natural blend of texts and modalities; * Efficient for both request-based workflows and batch jobs; * A powerful eval framework that thrives dimension explosions. Langfun is *simple and elegant*: * An intuitive programming model, graspable in 5 minutes; * Plug-and-play into any Python codebase, making an immediate difference; * Comprehensive LLMs under a unified API: Gemini, GPT, Claude, Llama3, and more. * Designed for agile developement: offering intellisense, easy debugging, with minimal overhead; ## Hello, Langfun ```python import langfun as lf import pyglove as pg from IPython import display class Item(pg.Object): name: str color: str class ImageDescription(pg.Object): items: list[Item] image = lf.Image.from_uri('https://upload.wikimedia.org/wikipedia/commons/thumb/8/83/Solar_system.jpg/1646px-Solar_system.jpg') display.display(image) desc = lf.query( 'Describe objects in {{my_image}} from top to bottom.', ImageDescription, lm=lf.llms.Gpt4o(api_key='<your-openai-api-key>'), my_image=image, ) print(desc) ``` *Output:* <img src="https://upload.wikimedia.org/wikipedia/commons/thumb/8/83/Solar_system.jpg/1646px-Solar_system.jpg" width="520px" alt="my_image"></img> ``` ImageDescription( items = [ 0 : Item( name = 'Mercury', color = 'Gray' ), 1 : Item( name = 'Venus', color = 'Yellow' ), 2 : Item( name = 'Earth', color = 'Blue and white' ), 3 : Item( name = 'Moon', color = 'Gray' ), 4 : Item( name = 'Mars', color = 'Red' ), 5 : Item( name = 'Jupiter', color = 'Brown and white' ), 6 : Item( name = 'Saturn', color = 'Yellowish-brown with rings' ), 7 : Item( name = 'Uranus', color = 'Light blue' ), 8 : Item( name = 'Neptune', color = 'Dark blue' ) ] ) ``` See [Langfun 101](https://colab.research.google.com/github/google/langfun/blob/main/docs/notebooks/langfun101.ipynb) for more examples. ## Install Langfun offers a range of features through [Extras](https://packaging.python.org/en/latest/tutorials/installing-packages/#installing-extras), allowing users to install only what they need. The minimal installation of Langfun requires only [PyGlove](https://github.com/google/pyglove), [Jinja2](https://github.com/pallets/jinja/), and [requests](https://github.com/psf/requests). To install Langfun with its minimal dependencies, use: ``` pip install langfun ``` For a complete installation with all dependencies, use: ``` pip install langfun[all] ``` To install a nightly build, include the `--pre` flag, like this: ``` pip install langfun[all] --pre ``` If you want to customize your installation, you can select specific features using package names like `langfun[X1, X2, ..., Xn]`, where `Xi` corresponds to a tag from the list below: | Tag | Description | | ------------------- | ---------------------------------------- | | all | All Langfun features. | | vertexai | VertexAI access. | | mime | All MIME supports. | | mime-pil | Image support for PIL. | | ui | UI enhancements | For example, to install a nightly build that includes VertexAI access, full modality support, and UI enhancements, use: ``` pip install langfun[vertexai,mime,ui] --pre ``` *Disclaimer: this is not an officially supported Google product.*
generative-ai-docs
> [!WARNING] > **This repository is deprecated and no longer maintained.** > > Please visit the following active resources: > * **Gemini Documentation**: [ai.google.dev/gemini-api/docs](https://ai.google.dev/gemini-api/docs) > * **Gemini Cookbook**: [github.com/google-gemini/cookbook](https://github.com/google-gemini/cookbook) > * **Gemma Cookbook**: [github.com/google-gemini/gemma-cookbook](https://github.com/google-gemini/gemma-cookbook) # [Deprecated] Google Gemini API Website & Documentation These are the source files for some guides and tutorials on the [Generative AI developer site](https://ai.google.dev/), home to the Gemini API and Gemma. | Path | Description | | ---- | ----------- | | [`site/`](site/) | Notebooks and other content used directly on ai.google.dev. | | [`demos/`](demos/) | Demos apps. Larger than examples, typically consists of working apps. | | [`examples/`](examples/) | Examples. Smaller, single-purpose code for demonstrating specific concepts. | ## License [Apache License 2.0](LICENSE)
iconvg
# IconVG *The canonical repository's location moved on February 2026, from github.com/google/iconvg to github.com/nigeltao/iconvg* IconVG is a compact, binary format for simple vector graphics: icons, logos, glyphs and emoji. **WARNING: THIS FORMAT IS EXPERIMENTAL AND SUBJECT TO INCOMPATIBLE CHANGES.** It is similar in concept to SVG (Scalable Vector Graphics) but much simpler. Compared to [SVG Tiny](https://www.w3.org/TR/SVGTiny12/), which isn't actually tiny, it does not have features for text, multimedia, interactivity, linking, scripting, animation, XSLT, DOM, combination with raster graphics such as JPEG formatted textures, etc. It is a format for efficient presentation, not an authoring format. For example, it does not provide grouping individual paths into higher level objects. Instead, the anticipated workflow is that artists use other tools and authoring formats like Inkscape and SVG, or commercial equivalents, and export IconVG versions of their assets, the same way that they would produce PNG versions of their vector art. It is not a goal to be able to recover the original SVG from a derived IconVG. It is not a pixel-exact format. Different implementations may produce slightly different renderings, due to implementation-specific rounding errors in the mathematical computations when rasterizing vector paths to pixels. Artifacts may appear when scaling up to extreme sizes, say 1 million by 1 million pixels. Nonetheless, at typical scales, e.g. up to 4096 × 4096, such differences are not expected to be perceptible to the naked eye. ## Example  - `cowbell.png` is 18555 bytes (256 × 256 pixels) - `cowbell.svg` is 4506 bytes - `cowbell.iconvg` is 1012 bytes (see also its [disassembly](./test/data/cowbell.iconvg.disassembly)) The [test/data](./test/data) directory holds these files and other examples. ## File Format - [IconVG Specification](spec/iconvg-spec.md) - Magic number: `0x8A 0x49 0x56 0x47`, which is `"\x8aIVG"`. - Suggested file extension: `.iconvg` - Suggested MIME type: `image/x-iconvg` ## Implementations This repository contains: - a decoder [written in C](./release/c) - a decoder [written in Dart](./src/dart), albeit for an [older (obsolete) version of the file format](https://github.com/google/iconvg/issues/4) - a low-level decoder [written in Go](./src/go). Low-level means that it outputs numbers (vector coordinates), not pixels. The [original Go IconVG package](https://pkg.go.dev/golang.org/x/exp/shiny/iconvg) also implements a decoder and encoder, albeit for an [older (obsolete) version of the file format](https://github.com/google/iconvg/issues/4). ## Disclaimer This is not an official Google product, it is just code that happens to be owned by Google. --- Updated on February 2026.