
tencent
Professional software vendor delivering innovative solutions on the Softono platform. Specialized in both open-source and proprietary software development.
Software by tencent

QMUI_Android
<p align="center"> <img src="https://cloud.githubusercontent.com/assets/1190261/26751376/63f96538-486a-11e7-81cf-5bc83a945207.png" width="220" height="220" alt="Banner" /> </p> # QMUI_Android QMUI Android 的设计目的是用于辅助快速搭建一个具备基本设计还原效果的 Android 项目,同时利用自身提供的丰富控件及兼容处理,让开发者能专注于业务需求而无需耗费精力在基础代码的设计上。不管是新项目的创建,或是已有项目的维护,均可使开发效率和项目质量得到大幅度提升。 [](https://github.com/QMUI "QMUI Team") [](http://opensource.org/licenses/MIT "Feel free to contribute.") ## 功能特性 ### 全局 UI 配置 只需要修改一份配置表就可以调整 App 的全局样式,包括组件颜色、导航栏、对话框、列表等。一处修改,全局生效。 ### 丰富的 UI 控件 提供丰富常用的 UI 控件,例如 BottomSheet、Tab、圆角 ImageView、下拉刷新等,使用方便灵活,并且支持自定义控件的样式。 ### 高效的工具方法 提供高效的工具方法,包括设备信息、屏幕信息、键盘管理、状态栏管理等,可以解决各种常见场景并大幅度提升开发效率。 ## 支持 Android 版本 QMUI Android 支持 API Level 21+。 ## 使用方法 可以在工程中的 qmuidemo 项目中查看各组件的使用。 ## 隐私与安全 1. 框架会调用 android.os.Build 下的字段读取 brand、model 等信息,用于区分不同的设备。 2. 框架会尝试读取系统设置获取是否是全面屏手势
QMUI_iOS
# QMUI iOS <p> <img src="https://user-images.githubusercontent.com/1190261/142202676-0b40a655-90b0-4aab-a761-f6a9185575bf.png" width="500" alt="Banner" /> </p> QMUI iOS 是一个致力于提高项目 UI 开发效率的解决方案,其设计目的是用于辅助快速搭建一个具备基本设计还原效果的 iOS 项目,同时利用自身提供的丰富控件及兼容处理, 让开发者能专注于业务需求而无需耗费精力在基础代码的设计上。不管是新项目的创建,或是已有项目的维护,均可使开发效率和项目质量得到大幅度提升。 [](https://github.com/QMUI "QMUI Team") [](http://opensource.org/licenses/MIT "Feel free to contribute.") 开发者:深圳市腾讯计算机系统有限公司 ## 功能特性 ### 全局 UI 配置 只需要修改一份配置表就可以调整 App 的全局样式,包括颜色、导航栏、输入框、列表等。一处修改,全局生效。 ### UIKit 拓展及版本兼容 拓展多个 UIKit 的组件,提供更加丰富的特性和功能,提高开发效率;解决不同 iOS 版本常见的兼容性问题。 ### 丰富的 UI 控件 提供丰富且常用的 UI 控件,使用方便灵活,并且支持自定义控件的样式。 ### 高效的工具方法及宏 提供高效的工具方法,包括设备信息、动态字体、键盘管理、状态栏管理等,可以解决各种常见场景并大幅度提升开发效率。 ## 支持iOS版本 1. 4.6.1 及以上,iOS 13+。 2. 4.4.0 及以上,iOS 11+。 3. 4.2.0 及以上,iOS 10+。 4. 3.0.0 及以上,iOS 9+。 5. 2.0.0 及以上,iOS 8+。 ## 使用方法 ``` pod 'QMUIKit' ``` ## 代码示例 请下载 QMUI Demo:[https://github.com/QMUI/QMUIDemo_iOS](https://github.com/QMUI/QMUIDemo_iOS)。  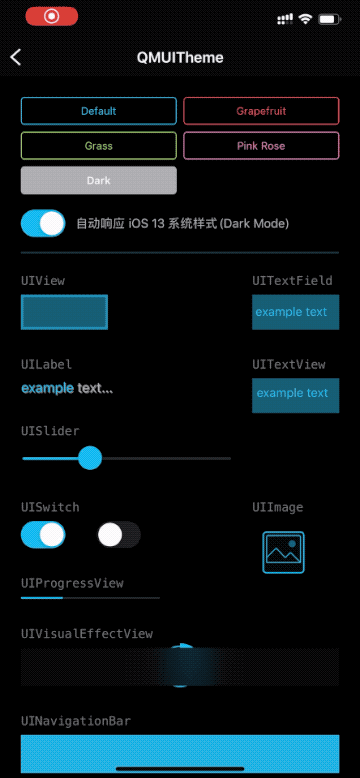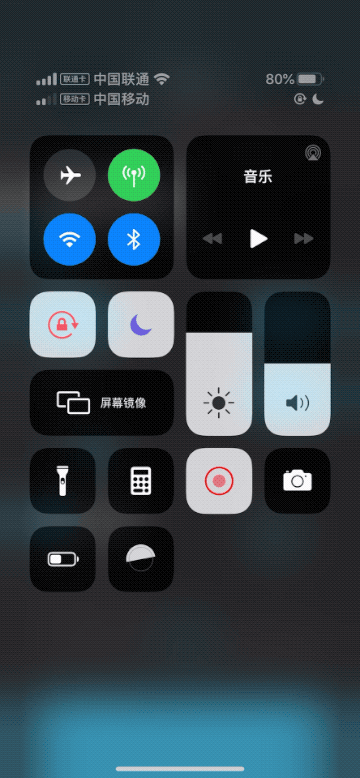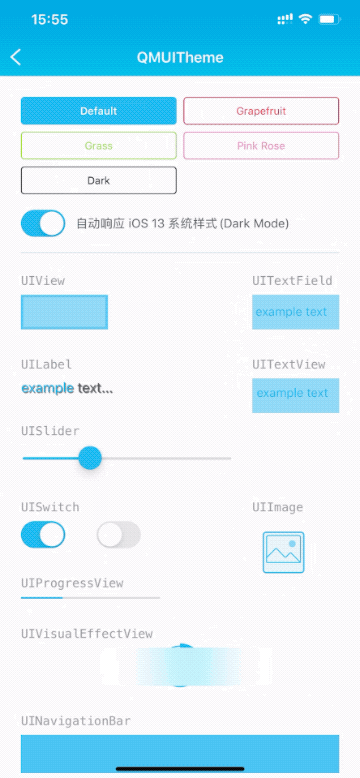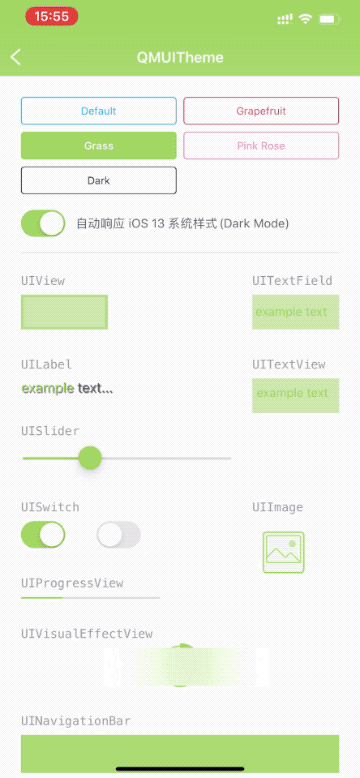   ## 注意事项 - 关于 AutoLayout:通常可以配合 Masonry 等常见的 AutoLayout 框架使用,若遇到不兼容的个案请提 issue。 - 关于 xib / storyboard:现已全面支持。 - 关于 Swift:可以正常使用,如遇到问题请提 issue。 - 关于 UIScene:暂不支持 Multiple Window。 ## 隐私政策 如果你想了解使用 QMUI iOS 过程中涉及到的隐私政策,可阅读:[QMUI iOS SDK 个人信息保护规则](https://github.com/Tencent/QMUI_iOS/wiki/QMUI-iOS-SDK%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF%E4%BF%9D%E6%8A%A4%E8%A7%84%E5%88%99)。 ## 设计资源 QMUIKit 框架内自带图片资源的组件主要是 QMUIConsole、QMUIEmotion、QMUIImagePicker、QMUITips,另外作为 Sample Code 使用的 QMUI Demo 是另一个独立的项目,它拥有自己另外一套设计。 QMUIKit 和 QMUI Demo 的 Sketch 设计稿均存放在 [https://github.com/QMUI/QMUIDemo_Design](https://github.com/QMUI/QMUIDemo_Design)。 ## 其他 建议搭配 QMUI 专用的 Code Snippets 及文件模板使用: 1. [QMUI_iOS_CodeSnippets](https://github.com/QMUI/QMUI_iOS_CodeSnippets) 2. [QMUI_iOS_Templates](https://github.com/QMUI/QMUI_iOS_Templates)
WeComponents
<img src="logo.png" width="400" height="100" /> WeComponents 是一个基于通用组件语言规范 (CLS) 实现的 Vue.js 声明式组件库,写完 JSON 就做好了页面,让开发更简单。</p> [](https://github.com/Tencent/WeComponents/blob/master/LICENSE) [](https://travis-ci.org/Tencent/WeComponents) [](https://coveralls.io/github/Tencent/WeComponents?branch=master) [](https://www.npmjs.com/package/@weadmin/wecomponents) ## 特点 设计思想上,以实现通用组件语言规范 CLS 为核心,即“将所有组件抽象为统一模型”,详见[通用组件语言规范](https://tencent.github.io/WeComponents/#/doc/principle/cls)。 **数据驱动** * UI 也是数据 * 以数据结构描述组件 * 以组件描述页面 **开发者友好** * 低门槛,学习了一种组件语言,就学会了整个组件库的使用 * 易理解,易记忆,易使用 **语义化** * 符合一般人对功能的认知 * 合适的场景,合适的支持 目前主要包含表单、列表、图表三类组件的实现,更多请查看[说明文档](https://tencent.github.io/WeComponents/)。 ## 使用说明 以 Vue.js 为例: ```javascript // 1. 引入组件库 import WeComponents from '@weadmin/wecomponents'; // 2. 声明页面组件 let pageFields = [ { component: 'input', label: '标题' } ]; // 3. 数据绑定 export default { data(){ return { // 初始化组件库 page: new WeComponents(this, pageFields) } } }; ``` ## 案例展示 以一个常见的查询列表需求为例。完整代码见[demo工程](https://github.com/weadmin/WeComponentsDemo)。 **需求背景**:提供一个*搜索框*,点击*查询按钮*后,展示*结果列表*,需要支持*翻页*。 **效果展示**:  **组件声明**: ```javascript [ { "component": "container", "items": [ { "component": "form", "attributes": { "layout": "row" }, "items": [ { "name": "search", "label": "搜索", "component": "input", "attributes": { "placeholder": "输入游戏名称进行搜索" } }, { "label": "查询", "component": "submit", "attributes": { "type": "primary" }, "events": { "submitEventName": "searchTable" } } ] }, { "id": "list", "component": "table", "attributes": { "placeholder": "暂无数据", "pagination": "default" }, "items": [ { "name": "icon", "label": "游戏图标", "attributes": { "width": 60, "textAlign": "center" }, "valueFilterName": "iconFilter" }, { "name": "name", "label": "游戏名称" }, { "name": "size", "label": "大小", "attributes": { "textAlign": "right" }, "valueFilterName": "sizeFilter" }, { "name": "intro", "label": "简介" }, { "label": "操作", "name": "option", "valueFilterName": "optionFilter" } ], "value": [ { "icon": "http://mmocgame.qpic.cn/wechatgame/HurH4elIxzLGX0FjtUic0kcQtloVbicTO6LVjWicWYwrIvUBSsve2KWz40jS2MFM5Zu/0", "name": "王者荣耀", "size": 3675556864, "intro": "爽快超神,腾讯5v5英雄公平对战手游" }, { "icon": "https://mmocgame.qpic.cn/wechatgame/duc2TvpEgSTLicunKH0MgcMLa8jicfvBvEXiaNAIReHzQJxhsibvgbVpIKtibgV8UcMEO/0", "name": "和平精英", "size": 3898905600, "intro": "大吉大利,腾讯光子自研军事竞赛体验" } ] } ] } ] ``` ## 参与贡献 如果你有好的意见或建议,欢迎给我们提 Issues 或 Pull Requests。 详见:[CONTRIBUTING.md](./CONTRIBUTING.md) [腾讯开源激励计划](https://opensource.tencent.com/contribution) 鼓励开发者的参与和贡献,期待你的加入。 ## License 所有代码采用 [MIT License](http://opensource.org/licenses/MIT) 开源,可根据自身团队和项目特点 `fork` 进行定制。
MMKV
[](https://github.com/Tencent/MMKV/blob/master/LICENSE.TXT) [](https://github.com/Tencent/MMKV/pulls) [](https://github.com/Tencent/MMKV/releases) [](https://github.com/Tencent/MMKV/wiki/home) 中文版本请参看[这里](./README_CN.md) MMKV is an **efficient**, **small**, **easy-to-use** mobile key-value storage framework used in the WeChat application. It's currently available on **Android**, **iOS/macOS**, **Windows**, **POSIX** and **HarmonyOS NEXT**. # MMKV for Android ## Features * **Efficient**. MMKV uses mmap to keep memory synced with files, and protobuf to encode/decode values, making the most of Android to achieve the best performance. * **Multi-Process concurrency**: MMKV supports concurrent read-read and read-write access between processes. * **Easy-to-use**. You can use MMKV as you go. All changes are saved immediately, no `sync`, no `apply` calls needed. * **Small**. * **A handful of files**: MMKV contains process locks, encode/decode helpers and mmap logics, and nothing more. It's really tidy. * **About 50K in binary size**: MMKV adds about 50K per architecture on App size, and much less when zipped (APK). ## Getting Started ### Installation Via Maven Add the following lines to `build.gradle` on your app module: ```gradle dependencies { implementation 'com.tencent:mmkv:2.4.0' // replace "2.4.0" with any available version } ``` Starting from v2.0.0, MMKV **no longer supports 32-bit** arch and API level 22 or 21, if you want 32-bit or API level 21~22, use v1.3.x LTS series. For other installation options, see [Android Setup](https://github.com/Tencent/MMKV/wiki/android_setup). ### Quick Tutorial You can use MMKV as you go. All changes are saved immediately, no `sync`, no `apply` calls needed. Setup MMKV on App startup, say your `Application` class, add these lines: ```Java public void onCreate() { super.onCreate(); String rootDir = MMKV.initialize(this); System.out.println("mmkv root: " + rootDir); //…… } ``` MMKV has a global instance, that can be used directly: ```Java import com.tencent.mmkv.MMKV; MMKV kv = MMKV.defaultMMKV(); kv.encode("bool", true); boolean bValue = kv.decodeBool("bool"); kv.encode("int", Integer.MIN_VALUE); int iValue = kv.decodeInt("int"); kv.encode("string", "Hello from mmkv"); String str = kv.decodeString("string"); ``` MMKV also supports **Multi-Process Access**. Full tutorials can be found here [Android Tutorial](https://github.com/Tencent/MMKV/wiki/android_tutorial). ## Performance Writing random `int` for 1000 times, we get this chart:  For more benchmark data, please refer to [our benchmark](https://github.com/Tencent/MMKV/wiki/android_benchmark). # MMKV for iOS/macOS ## Features * **Efficient**. MMKV uses mmap to keep memory synced with files, and protobuf to encode/decode values, making the most of iOS/macOS to achieve the best performance. * **Easy-to-use**. You can use MMKV as you go, no configurations are needed. All changes are saved immediately, no `synchronize` calls are needed. * **Small**. * **A handful of files**: MMKV contains encode/decode helpers and mmap logics and nothing more. It's really tidy. * **Less than 30K in binary size**: MMKV adds less than 30K per architecture on App size, and much less when zipped (IPA). ## Getting Started ### Installation Via CocoaPods: 1. Install [CocoaPods](https://guides.CocoaPods.org/using/getting-started.html); 2. Open the terminal, `cd` to your project directory, run `pod repo update` to make CocoaPods aware of the latest available MMKV versions; 3. Edit your Podfile, add `pod 'MMKV'` to your app target; 4. Run `pod install`; 5. Open the `.xcworkspace` file generated by CocoaPods; 6. Add `#import <MMKV/MMKV.h>` to your source file and we are done. For other installation options, see [iOS/macOS Setup](https://github.com/Tencent/MMKV/wiki/iOS_setup). ### Quick Tutorial You can use MMKV as you go, no configurations are needed. All changes are saved immediately, no `synchronize` calls are needed. Setup MMKV on App startup, in your `-[MyApp application: didFinishLaunchingWithOptions:]`, add these lines: ```objective-c - (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions { // init MMKV in the main thread [MMKV initializeMMKV:nil]; //... return YES; } ``` MMKV has a global instance, that can be used directly: ```objective-c MMKV *mmkv = [MMKV defaultMMKV]; [mmkv setBool:YES forKey:@"bool"]; BOOL bValue = [mmkv getBoolForKey:@"bool"]; [mmkv setInt32:-1024 forKey:@"int32"]; int32_t iValue = [mmkv getInt32ForKey:@"int32"]; [mmkv setString:@"hello, mmkv" forKey:@"string"]; NSString *str = [mmkv getStringForKey:@"string"]; ``` MMKV also supports **Multi-Process Access**. Full tutorials can be found [here](https://github.com/Tencent/MMKV/wiki/iOS_tutorial). ## Performance Writing random `int` for 10000 times, we get this chart:  For more benchmark data, please refer to [our benchmark](https://github.com/Tencent/MMKV/wiki/iOS_benchmark). # MMKV for Windows ## Features * **Efficient**. MMKV uses mmap to keep memory synced with files, and protobuf to encode/decode values, making the most of Windows to achieve the best performance. * **Multi-Process concurrency**: MMKV supports concurrent read-read and read-write access between processes. * **Easy-to-use**. You can use MMKV as you go. All changes are saved immediately, no `save`, no `sync` calls are needed. * **Small**. * **A handful of files**: MMKV contains process locks, encode/decode helpers and mmap logics, and nothing more. It's really tidy. * **About 10K in binary size**: MMKV adds about 10K on application size, and much less when zipped. ## Getting Started ### Installation Via Source 1. Getting source code from git repository: ``` git clone https://github.com/Tencent/MMKV.git ``` 2. Add `Core/core.vcxproj` to your solution; 3. Add `MMKV` project to your project's dependencies; 4. Add `$(OutDir)include` to your project's `C/C++` -> `General` -> `Additional Include Directories`; 5. Add `$(OutDir)` to your project's `Linker` -> `General` -> `Additional Library Directories`; 6. Add `mmkv.lib` to your project's `Linker` -> `Input` -> `Additional Dependencies`; 7. Add `#include <MMKV/MMKV.h>` to your source file and we are done. note: 1. MMKV is compiled with `MT/MTd` runtime by default. If your project uses `MD/MDd`, you should change MMKV's setting to match your project's (`C/C++` -> `Code Generation` -> `Runtime Library`), or vice versa. 2. MMKV is developed with Visual Studio 2017, change the `Platform Toolset` if you use a different version of Visual Studio. For other installation options, see [Windows Setup](https://github.com/Tencent/MMKV/wiki/windows_setup). ### Quick Tutorial You can use MMKV as you go. All changes are saved immediately, no `sync`, no `save` calls needed. Setup MMKV on App startup, say in your `main()`, add these lines: ```C++ #include <MMKV/MMKV.h> int main() { std::wstring rootDir = getYourAppDocumentDir(); MMKV::initializeMMKV(rootDir); //... } ``` MMKV has a global instance, that can be used directly: ```C++ auto mmkv = MMKV::defaultMMKV(); mmkv->set(true, "bool"); std::cout << "bool = " << mmkv->getBool("bool") << std::endl; mmkv->set(1024, "int32"); std::cout << "int32 = " << mmkv->getInt32("int32") << std::endl; mmkv->set("Hello, MMKV for Windows", "string"); std::string result; mmkv->getString("string", result); std::cout << "string = " << result << std::endl; ``` MMKV also supports **Multi-Process Access**. Full tutorials can be found here [Windows Tutorial](https://github.com/Tencent/MMKV/wiki/windows_tutorial). # MMKV for POSIX ## Features * **Efficient**. MMKV uses mmap to keep memory synced with files, and protobuf to encode/decode values, making the most of POSIX to achieve the best performance. * **Multi-Process concurrency**: MMKV supports concurrent read-read and read-write access between processes. * **Easy-to-use**. You can use MMKV as you go. All changes are saved immediately, no `save`, no `sync` calls are needed. * **Small**. * **A handful of files**: MMKV contains process locks, encode/decode helpers and mmap logics, and nothing more. It's really tidy. * **About 7K in binary size**: MMKV adds about 7K on application size, and much less when zipped. ## Getting Started ### Installation Via CMake 1. Getting source code from the git repository: ``` git clone https://github.com/Tencent/MMKV.git ``` 2. Edit your `CMakeLists.txt`, add those lines: ```cmake add_subdirectory(mmkv/POSIX/src mmkv) target_link_libraries(MyApp mmkv) ``` 3. Add `#include "MMKV.h"` to your source file and we are done. For other installation options, see [POSIX Setup](https://github.com/Tencent/MMKV/wiki/posix_setup). ### Quick Tutorial You can use MMKV as you go. All changes are saved immediately, no `sync`, no `save` calls needed. Setup MMKV on App startup, say in your `main()`, add these lines: ```C++ #include "MMKV.h" int main() { std::string rootDir = getYourAppDocumentDir(); MMKV::initializeMMKV(rootDir); //... } ``` MMKV has a global instance, that can be used directly: ```C++ auto mmkv = MMKV::defaultMMKV(); mmkv->set(true, "bool"); std::cout << "bool = " << mmkv->getBool("bool") << std::endl; mmkv->set(1024, "int32"); std::cout << "int32 = " << mmkv->getInt32("int32") << std::endl; mmkv->set("Hello, MMKV for Windows", "string"); std::string result; mmkv->getString("string", result); std::cout << "string = " << result << std::endl; ``` MMKV also supports **Multi-Process Access**. Full tutorials can be found here [POSIX Tutorial](https://github.com/Tencent/MMKV/wiki/posix_tutorial). # MMKV for HarmonyOS NEXT ## Features * **Efficient**. MMKV uses mmap to keep memory synced with file, and protobuf to encode/decode values, making the most of native platform to achieve best performance. * **Multi-Process concurrency**: MMKV supports concurrent read-read and read-write access between processes. * **Easy-to-use**. You can use MMKV as you go. All changes are saved immediately, no `sync`, no `flush` calls needed. * **Small**. * **A handful of files**: MMKV contains process locks, encode/decode helpers and mmap logics and nothing more. It's really tidy. * **About 600K in binary size**: MMKV adds about 600K per architecture on App size, and much less when zipped (HAR/HAP). ## Getting Started ### Installation via OHPM: ```bash ohpm install @tencent/mmkv ``` ### Quick Tutorial You can use MMKV as you go. All changes are saved immediately, no `sync`, no `apply` calls needed. Setup MMKV on App startup, say your `EntryAbility.onCreate()` function, add these lines: ```js import { MMKV } from '@tencent/mmkv'; export default class EntryAbility extends UIAbility { onCreate(want: Want, launchParam: AbilityConstant.LaunchParam): void { let appCtx = this.context.getApplicationContext(); let mmkvRootDir = MMKV.initialize(appCtx); console.info('mmkv rootDir: ', mmkvRootDir); …… } ``` MMKV has a global instance, that can be used directly: ```js import { MMKV } from '@tencent/mmkv'; let mmkv = MMKV.defaultMMKV(); mmkv.encodeBool('bool', true); console.info('bool = ', mmkv.decodeBool('bool')); mmkv.encodeInt32('int32', Math.pow(2, 31) - 1); console.info('max int32 = ', mmkv.decodeInt32('int32')); mmkv.encodeInt64('int', BigInt(2**63) - BigInt(1)); console.info('max int64 = ', mmkv.decodeInt64('int')); let str: string = 'Hello OpenHarmony from MMKV'; mmkv.encodeString('string', str); console.info('string = ', mmkv.decodeString('string')); let arrayBuffer: ArrayBuffer = StringToArrayBuffer('Hello OpenHarmony from MMKV with bytes'); mmkv.encodeBytes('bytes', arrayBuffer); let bytes = mmkv.decodeBytes('bytes'); console.info('bytes = ', ArrayBufferToString(bytes)); ``` As you can see, MMKV is quite easy to use. For the full documentation, see [HarmonyOS NEXT Tutorial](https://github.com/Tencent/MMKV/wiki/ohos_setup). ## License MMKV is published under the BSD 3-Clause license. For details check out the [LICENSE.TXT](./LICENSE.TXT). ## Change Log Check out the [CHANGELOG.md](./CHANGELOG.md) for details of change history. ## Contributing If you are interested in contributing, check out the [CONTRIBUTING.md](./CONTRIBUTING.md), also join our [Tencent OpenSource Plan](https://opensource.tencent.com/contribution). MMKV has officially joined the [Tencent Device-oriented Service Product Alliance](https://tds-union.qq.com/), working together with other alliance members to build an open and mutually beneficial frontend technology product ecosystem. To give clarity of what is expected of our members, MMKV has adopted the code of conduct defined by the Contributor Covenant, which is widely used. And we think it articulates our values well. For more, check out the [Code of Conduct](./CODE_OF_CONDUCT.md). ## FAQ & Feedback Check out the [FAQ](https://github.com/Tencent/MMKV/wiki/FAQ) first. Should there be any questions, don't hesitate to create [issues](https://github.com/Tencent/MMKV/issues). ## Personal Information Protection Rules User privacy is taken very seriously: MMKV does not obtain, collect or upload any personal information. Please refer to the [MMKV SDK Personal Information Protection Rules](https://support.weixin.qq.com/cgi-bin/mmsupportacctnodeweb-bin/pages/aY5BAtRiO1BpoHxo) for details.
mxflutter
 ---- # MXFlutter Beta v0.9.0 MXFlutter 是一套使用 TypeScript/JavaScript 来开发 Flutter 应用的框架。 框架支持两种开发方式 1. 基于 mxflutter-js 前端框架,使用 TypeScript 语言,以类似 Flutter 的 Widget 组装方式开发UI,借助前端生态的基础能力,开发App。(前端框架已开源: [github:mxflutter-js](https://github.com/mxflutter/mxflutter-js)) 2. 不改变现有 Flutter 的开发方式,使用 MXJSCompiler 把现有工程编译为JS,运行在 mxflutter 框架之上。( MXJSCompiler JS编译工具在开源计划中 ) 可以安装 Android的包来体验 [MXFlutter_v0-9-0.apk](https://github.com/mxflutter/awesome_mxflutter/releases/download/v0.9.0/awesome-mxflutter-0-9-0.apk)。 接入的详细步骤,请参阅 [mxflutter 接入指南](Documentation/接入指南.md) #### 版本对应关系 | v0.9.0 | Flutter 1.22.3 | | --- | --- | | [v0.8.0](https://github.com/mxflutter/mxflutter) | Flutter 1.20.3 | #### 相关代码库 | 代码库 | 简介 | 地址 | | --- | --- | --- | | mxflutter | Flutter Plugin ,使用JS Bundle 渲染页面 | https://github.com/tencent/mxflutter.git | | mxflutter-js | TS 前端框架,支撑使用Flutter Widget 组装方式开发UI | https://github.com/mxflutter/mxflutter-js | | mxflutter_pkg | mxflutter 第三方Package支持的示例 | https://github.com/mxflutter/mxflutter_pkg | | awesome_mxflutter | Flutter 示例工程,演示如何运行JS Bundle | https://github.com/mxflutter/awesome_mxflutter | | mxflutter-js-demo | JS 示例工程,演示如何使用TS开发Flutter | https://github.com/mxflutter/mxflutter-js-demo | | mx_mirror_builder | 辅助工具,用于生成 TS 类定义和 Mirror 映射 | https://github.com/mxflutter/mx_mirror_builder | ##### **重要提示:MXFlutter目前处于开发阶段, MXFlutter 针对自己业务用到的 Widget 和 Api 进行了验证和测试,但因 Flutter Widget 数量太多,团队人力有限,无法对所有提供的 Widget 进行支持和功能验证,所以把代码开源出来,有需要的团队可以一起来完善和演进。如在生产环境使用,确保理解MXFlutter运行原理,并对业务使用到的TS Widget进行完整测试,也欢迎贡献测试完成的名单。** --- * [一、介绍](#title1) * [二、应用](#title2) * [三、特性](#title3) * [四、设计思路](#title3) * [五、架构](#title4) * [六、如何使用](#title5) * [接入指南](#title5_1) * [七、许可协议](#title7) * [八、参与贡献](#title8) * [九、联系我们](#title9) ---- ## <a name="title1">一、介绍</a> MXFlutter 是一套使用 TypeScript/JavaScript 来开发 Flutter 应用的框架。 MXFlutter 在前端方向目前已经实现了使用 TypeScript 来编写,使用 Flutter Widget 的描述方式来开发业务。可以接入前端 npm 生态,并提供和 Flutter 原生十分接近的编码方式和语法提示等。MXFlutter 前端方向的未来规划是,实现 web前端 dom + css 的开发方式来接入 Flutter,通过 Vue / React 等前端熟悉的开发框架来编写业务代码,自动转换为 Flutter Widget 进行渲染,实现前端开发者的零成本接入。 MXFlutter 在终端方向的思路使用 MXJSCompiler 把现有 Flutter 工程编译为JS,运行在 MXFlutter 框架之上。以 ReactNative 框架为参照, JS引擎的性能可以支撑大型App的运行。MXJSCompiler 编译工具目前在建设中,会在后续版本稳定之后开源。 ## <a name="title2">二、应用</a>  ## <a name="title3">三、特性</a> * 支持 TypeScript 语言和前端生态 * 支持 Flutter 中同名 Widget 类,相同API,已提供部分开发示例 * 支持 Flutter 相同的 Build 方式,setState刷新及事件响应方法 * 支持 JS 和 Dart 双向调用通道 * 支持模拟器页面hot reload * 支持 Safari 和 Chrome 调试 * 支持编译现有Flutter工程为JS,运行在框架之上 ## <a name="title4">四、设计思路</a> 把 Flutter 的渲染逻辑中的三棵树(即:WidgetTree、Element、RenderObject )中的第一棵(即:WidgetTree),放到 JavaScript 中生成。用 JavaScript 完整实现了 Flutter 控件层封装,实现了轻量的响应式 UI 框架,支撑JS WidgetTree 的 build 逻辑,build 过程生成的UI描述, 通过Flutter 层的 UI 引擎转换成真正的 Flutter 控件显示出来。 ## <a name="title5">五、架构</a> 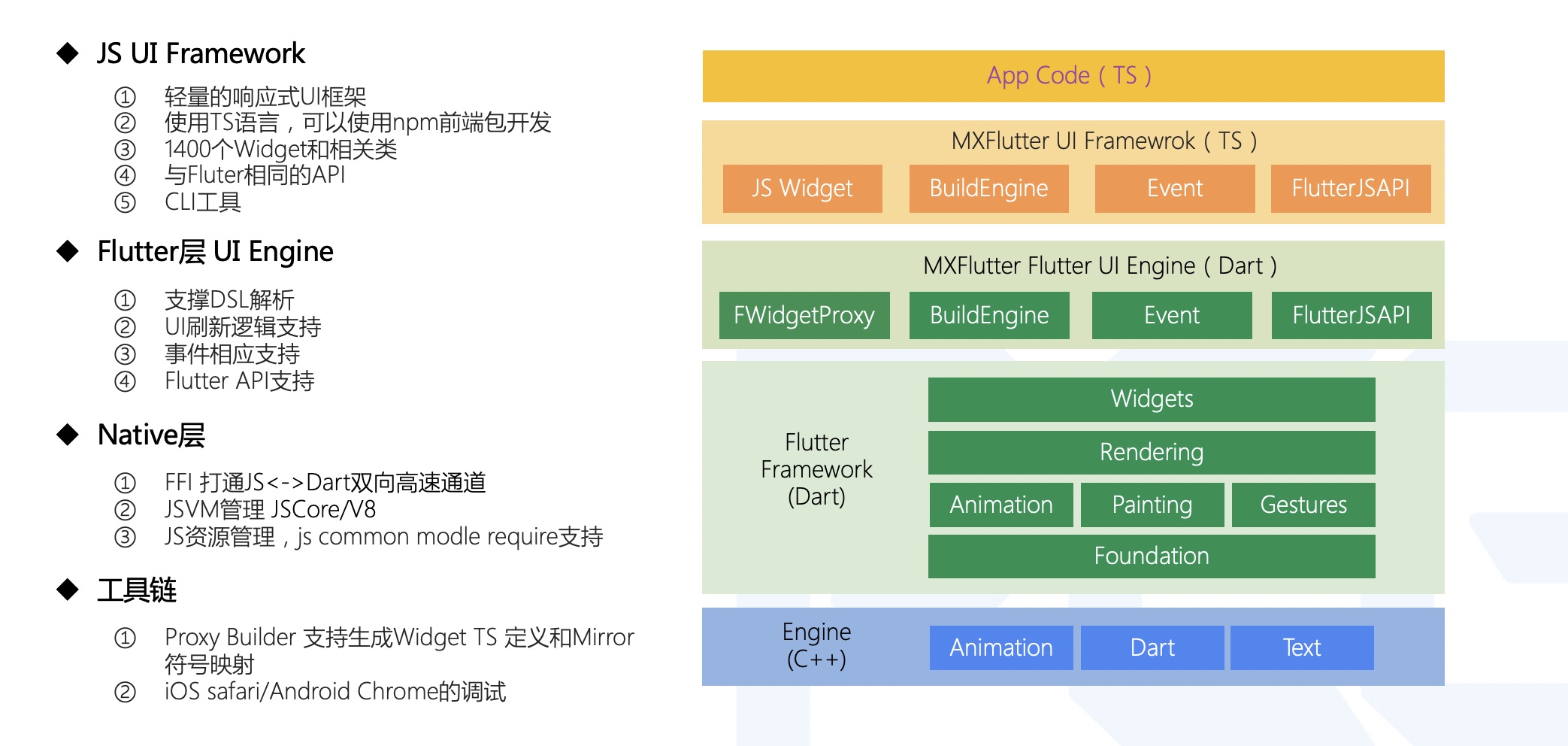 ## <a name="title6">六、如何使用</a> ### MXFlutter使用 从0.7.0版本开始,MXFlutter 最大的变化是开发语言切换到了 TypeScript,接入了npm生态,相比原来裸写JS的开发方式,向前端生态靠拢。这样就解决了之前版本最痛的没有代码提示和静态检查的问题。 MXFlutter 框架分为两部分,上层是 TypeScript 开发的 MXFlutter 前端框架,用于支撑使用TS来开发App,底层是Flutter开发的 MXFlutter Flutter Plugin,用于UI渲染。 接入三部曲: * 第一步 在你的 Flutter 工程里引入 mxflutter flutter plugin。 * 第二步 用 mxflutter cli 工具新建一个 TypeScript 的 mxflutter 工程。 开发完成之后编译输出JS Bundle文件。 * 第三步 把 TS 工程编译的bundle-xxx.js 放置在你的Flutter工程制定目录下,然后就可以调用 mxflutter 提供的接口打开 TS 页面了。 接入的详细步骤,请参阅 [mxflutter 接入指南](Documentation/接入指南.md) 接入示例工程1 [示例工程](./example) 接入示例工程2 [awesome-mxflutter](https://github.com/mxflutter/awesome_mxflutter) ## <a name="title7">七、许可协议</a> MXFlutter遵循[BSD](./LICENSE)开源许可证协议。 ## <a name="title8">八、参与贡献</a> MXFlutter还需要很多工作去完善功能,修改BUG,建设配套设施,如果大家有兴趣,欢迎加入一起开发。 如果你有好的想法或建议,也欢迎给我们提 `Issues` 或 `Pull Requests`。 ## <a name="title9">九、联系我们</a> `MXFlutter Team` 是一个技术氛围浓厚,有美女有帅哥有趣有爱的团队,欢迎终端,后台,前端同学投递简历哦:[email protected] 对MXFlutter有兴趣的小伙伴,可以加群交流 QQ群:747535761 
WeKnora
<p align="center"> <picture> <img src="./docs/images/logo.png" alt="WeKnora Logo" height="120"/> </picture> </p> <p align="center"> <picture> <a href="https://trendshift.io/repositories/15289" target="_blank"> <img src="https://trendshift.io/api/badge/repositories/15289" alt="Tencent%2FWeKnora | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/> </a> </picture> </p> <p align="center"> <a href="https://weknora.weixin.qq.com" target="_blank"> <img alt="Official Website" src="https://img.shields.io/badge/Official Website-WeKnora-4e6b99"> </a> <a href="https://chatbot.weixin.qq.com" target="_blank"> <img alt="WeChat Dialog Open Platform" src="https://img.shields.io/badge/WeChat Dialog Open Platform-5ac725"> </a> <a href="https://chromewebstore.google.com/detail/jpemjbopikggjlmikmclgbmkhhopjdgd" target="_blank"> <img alt="Chrome Extension" src="https://img.shields.io/badge/Chrome Extension-WeKnora-4285F4"> </a> <a href="https://clawhub.ai/lyingbug/weknora" target="_blank"> <img alt="ClawHub Skill" src="https://img.shields.io/badge/ClawHub Skill-WeKnora-ff6b35"> </a> <a href="https://github.com/Tencent/WeKnora/blob/main/LICENSE"> <img src="https://img.shields.io/badge/License-MIT-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="License"> </a> <a href="./CHANGELOG.md"> <img alt="Version" src="https://img.shields.io/badge/version-0.6.2-2e6cc4?labelColor=d4eaf7"> </a> </p> <p align="center"> | <b>English</b> | <a href="./README_CN.md"><b>简体中文</b></a> | <a href="./README_JA.md"><b>日本語</b></a> | <a href="./README_KO.md"><b>한국어</b></a> | </p> <p align="center"> <h4 align="center"> [Overview](#-overview) • [Architecture](#-architecture) • [Key Features](#-key-features) • [Getting Started](#-getting-started) • [API Reference](#-api-reference) • [Developer Guide](#-developer-guide) </h4> </p> # 💡 WeKnora — Turn Documents into Living Knowledge with RAG, Agents and Auto-Wiki ## 📌 Overview [**WeKnora**](https://weknora.weixin.qq.com) is an open-source, LLM-powered knowledge framework built for enterprise-grade document understanding, semantic retrieval, and autonomous reasoning. It is organized around three core capabilities: **RAG-based Quick Q&A** for everyday lookups, a **ReAct Agent** that autonomously orchestrates retrieval, MCP tools and web search to handle complex multi-step tasks, and a brand-new **Wiki Mode** in which agents distill raw documents into a self-maintaining, interlinked markdown knowledge base with an interactive knowledge graph. Combined with multi-source ingestion (Feishu / Notion / Yuque, and growing), 20+ LLM provider integrations, full Langfuse observability, **enterprise-ready multi-tenant RBAC** (4-tier role matrix + per-resource ownership + per-tenant audit log), and a fully self-hostable modular architecture, WeKnora turns scattered documents into a queryable, reasoning-capable, continuously evolving knowledge asset. The framework supports auto-syncing knowledge from Feishu, Notion, and Yuque (more data sources coming soon), handles 10+ document formats including PDF, Word, images, and Excel, and can serve Q&A directly through IM channels like WeCom, Feishu, Slack, and Telegram. It is compatible with major LLM providers including OpenAI, DeepSeek, Qwen (Alibaba Cloud), Zhipu, Hunyuan, Gemini, MiniMax, NVIDIA, and Ollama. Its fully modular design allows swapping LLMs, vector databases, and storage backends, with support for local and private cloud deployment ensuring complete data sovereignty. WeKnora also integrates with **Langfuse** for comprehensive observability into agent reasoning, token usage, and pipeline tracing. ## ✨ Latest Updates - **v0.6.2** — Per-upload process configuration with upload-confirm dialog; document reparse with `process_config`; `weknora` CLI v0.9 (bundled Agent Skills, `session stop`, auth/profile harmonization); KB marquee multi-select; HNSW index for 1024-dim pgvector embeddings; chat resources store refactor; Langfuse-only tracing (Jaeger removed). See [`CHANGELOG.md`](./CHANGELOG.md). - **v0.6.1** — Document parsing trace timeline (Langfuse-style span tree with stage-by-stage progress + stop-parse); OpenSearch vector store driver; declarative built-in models via YAML; system admin & consolidated platform settings + audit log; new-user onboarding guide; settings UI redesign; `weknora` CLI v0.7 / v0.8 (agent-first wire contract, NDJSON, `--dry-run`); OpenDataLoader + PaddleOCR-VL parsers; MCP server multi-transport (stdio / SSE / HTTP); per-model thinking-mode config; Tencent LKEAP rerank + native Gemini embeddings + MiniMax-M3. See [`CHANGELOG.md`](./CHANGELOG.md). - **v0.6.0** — Tenant RBAC (4-tier role matrix `Owner` / `Admin` / `Contributor` / `Viewer` + per-KB ownership + per-tenant audit log), tenant member management & multi-workspace UX, self-service workspaces; `weknora` CLI v0.4 GA with `mcp serve`; KB retrieval fan-out across vector stores; AES-256-GCM credential encryption + docreader gRPC TLS + Token; Zhipu embedder + Huawei OBS; server-side user preferences; Go 1.26.0. See [`docs/RBAC说明.md`](./docs/RBAC说明.md) and [`CHANGELOG.md`](./CHANGELOG.md). - **v0.5.2** — Wiki ingest scales to 40k-document KBs (task queue + DLQ); MCP human-in-the-loop tool approval; Anthropic / Apache Doris / Tencent VectorDB / KS3 / SearXNG backends; adaptive 3-tier chunking with live preview; global ⌘K command palette; Yuque connector + WeChat Mini Program; `weknora` CLI preview. - **v0.5.1** — Knowledge-base batch management; tenant-wide IM channels overview; session search + user-scoped pinning; unified Model / Web Search / MCP settings cards; per-agent LLM timeout; desktop tenant switching. - **v0.5.0** — Wiki Mode GA — agents auto-generate structured, interlinked Markdown wiki pages with a knowledge graph; wiki browser + visual graph in the UI. - **v0.4.0** — WeKnora Cloud (hosted LLM + parsing); Chrome Extension; ClawHub Skill; WeChat IM; attachment processing; Azure OpenAI / Alibaba OSS; Notion connector; Baidu + Ollama web search; VectorStore management. - **v0.3.6** — ASR (audio); Feishu data-source auto-sync; OIDC; IM quote-reply context + thread-based sessions; document summarization; Tavily search; parallel tool calling; agent @mention scope restriction. - **v0.3.5** — Telegram / DingTalk / Mattermost IM; IM slash commands + QA queue; suggested questions; VLM auto-describe MCP tool images; Novita AI; channel tracking. - **v0.3.4** — WeCom / Feishu / Slack IM; multimodal image support; NVIDIA model API; Weaviate; AWS S3; AES-256-GCM API-key encryption; built-in MCP service; hybrid-search optimization; `final_answer` tool. - **v0.3.3** — Parent-child chunking; KB pinning; fallback response; passage cleaning for rerank; storage auto-creation; Milvus. - **v0.3.2** — Knowledge Search entry; per-source parser & storage engine config; image rendering in local storage; document preview; Volcengine TOS; Mermaid rendering; batch session management; memory graph preview. - **v0.3.0** — Shared Space; Agent Skills + sandboxed execution; custom agents; Data Analyst agent; thinking mode; Bing / Google web search; API Key auth; Helm chart; Korean i18n; Qdrant. - **v0.2.0** — Agent Mode (ReACT); multi-type knowledge bases (FAQ + document); conversation strategy config; DuckDuckGo web search; MCP tool integration; new UI with agent mode switching; MQ async task management. ## 📱 Interface Showcase <table> <tr> <td colspan="2" align="center"><b>💬 Intelligent Q&A Conversation</b><br/><img src="./docs/images/qa.png" alt="Intelligent Q&A Conversation" width="100%"></td> </tr> <tr> <td width="50%" align="center"><b>📖 Wiki Browser</b><br/><img src="./docs/images/wiki-browser.png" alt="Wiki Browser" width="100%"></td> <td width="50%" align="center"><b>🕸️ Wiki Knowledge Graph</b><br/><img src="./docs/images/wiki-graph.png" alt="Wiki Knowledge Graph" width="100%"></td> </tr> <tr> <td width="50%" align="center"><b>🤖 Agent Mode · Tool Call Process</b><br/><img src="./docs/images/agent-qa.png" alt="Agent Mode Tool Call Process" width="100%"></td> <td width="50%" align="center"><b>⚙️ Conversation Settings</b><br/><img src="./docs/images/settings.png" alt="Conversation Settings" width="100%"></td> </tr> <tr> <td colspan="2" align="center"><b>🔭 Observability · Langfuse Tracing</b><br/><img src="./docs/images/langfuse.png" alt="Observability Langfuse Tracing" width="100%"></td> </tr> </table> ## 🏗️ Architecture  Fully modular pipeline from document parsing, vectorization, and retrieval to LLM inference — every component is swappable and extensible. Supports local / private cloud deployment with full data sovereignty and a zero-barrier Web UI for quick onboarding. ## 🧩 Feature Overview **Intelligent Conversation** | Capability | Details | |------------|---------| | Intelligent Reasoning | ReACT progressive multi-step reasoning, autonomously orchestrating knowledge retrieval, MCP tools, and web search; custom agent support | | Quick Q&A | RAG-based Q&A over knowledge bases for fast and accurate answers | | Wiki Mode | Agent-driven auto-generation of structured, interlinked markdown Wiki pages from raw documents | | Tool Calling | Built-in tools, MCP tools, web search | | Conversation Strategy | Online Prompt editing, retrieval threshold tuning, multi-turn context awareness | | Suggested Questions | Auto-generated question suggestions based on knowledge base content | **Knowledge Management** | Capability | Details | |------------|---------| | Knowledge Base Types | FAQ / Document / Wiki with folder import, URL import, tag management, and online entry | | Per-Upload Process Config | Override parser, chunking, multimodal (VLM / ASR), graph extraction, and question generation per upload batch via upload-confirm dialog or `process_config` API; reparse with new settings | | Data Source Import | Auto-sync from Feishu / Notion / Yuque (more data sources coming soon); incremental and full sync | | Document Formats | PDF / Word / Txt / Markdown / HTML / Images / CSV / Excel / PPT / JSON | | Retrieval Strategies | BM25 sparse / Dense retrieval / GraphRAG / parent-child chunking / HNSW-accelerated pgvector (1024-dim) / multi-dimensional indexing | | Batch Selection | Marquee drag-select multiple documents in the KB list for batch operations | | E2E Testing | Full-pipeline visualization with recall hit rate, BLEU / ROUGE metric evaluation | **Integrations & Extensions** | Capability | Details | |------------|---------| | LLMs | OpenAI / Azure OpenAI / Anthropic (Claude) / DeepSeek / Qwen (Alibaba Cloud) / Zhipu / Hunyuan / Doubao (Volcengine) / Gemini / MiniMax / NVIDIA / Novita AI / SiliconFlow / OpenRouter / Ollama | | Embeddings | Ollama / BGE / GTE / Zhipu / OpenAI-compatible APIs | | Vector DBs | PostgreSQL (pgvector) / Elasticsearch / OpenSearch / Milvus / Weaviate / Qdrant / Apache Doris / Tencent VectorDB | | Object Storage | Local / MinIO / AWS S3 / Volcengine TOS / Alibaba Cloud OSS / Kingsoft Cloud KS3 / Huawei Cloud OBS | | IM Channels | WeCom / Feishu / Slack / Telegram / DingTalk / Mattermost / WeChat | | Web Search | DuckDuckGo / Bing / Google / Tavily / Baidu / Ollama / SearXNG | **Platform** | Capability | Details | |------------|---------| | Deployment | Local / Docker / Kubernetes (Helm) with private and offline support | | UI | Web UI / RESTful API / CLI (`weknora`) / Chrome Extension / WeChat Mini Program | | Access Control | Tenant RBAC with 4-tier role matrix (Owner / Admin / Contributor / Viewer), per-KB resource ownership, per-tenant audit log, invite-only workspaces, self-service tenant creation, cross-tenant superuser | | Security | AES-256-GCM at-rest encryption for API keys and MCP / data-source credentials with graceful key rotation; gRPC TLS + Token between app and docreader; SSRF-safe HTTP client; sandbox isolation for agent skills | | Observability | Integrated Langfuse (sole tracing backend) for ReAct loops, token tracking, tool calls, and pipeline tracing; built-in Langfuse-style document parsing trace timeline with stage-by-stage progress | | Task Management | MQ async tasks, automatic database migration on version upgrade | | Model Management | Centralized config, declarative built-in models via YAML, per-knowledge-base model selection, per-model thinking-mode config, multi-tenant built-in model sharing, WeKnora Cloud hosted models and parsing | ## 🧩 Chrome Extension [**WeKnora Chrome Extension**](https://chromewebstore.google.com/detail/jpemjbopikggjlmikmclgbmkhhopjdgd) lets you capture web content directly into your WeKnora knowledge base. Select text, images, or entire pages in the browser and save them as knowledge entries with one click — no copy-paste or file upload needed. ## 📱 WeChat Mini Program The [WeKnora Mini Program](./miniprogram/README.md) provides a lightweight mobile client for configuring WeKnora API access, selecting knowledge bases, importing URLs, and asking knowledge chat from WeChat. ## 🦞 ClawHub Skill [**WeKnora ClawHub Skill**](https://clawhub.ai/lyingbug/weknora) is a WeKnora skill published on the ClawHub platform. Once installed, it enables document import (file / URL / Markdown), hybrid search (vector + keyword) across knowledge bases, and knowledge entry management — all through the WeKnora REST API. - **Document Import** — Upload files, import web pages, or write Markdown knowledge via the agent - **Hybrid Search** — Search within or across knowledge bases with vector + keyword retrieval - **Knowledge Management** — List, browse, edit, and delete knowledge entries programmatically ## ⌨️ Command-Line Interface `weknora` is the official CLI for driving the API from a terminal or AI agent. The command surface mirrors `gh` CLI's `<noun> <verb>` convention; output is human-readable by default and switches to a stable JSON envelope with `--json`. v0.9 ships bundled Agent Skills (`weknora-rag-search`, `weknora-shared`), adds `session stop`, and harmonizes auth/profile workflows (see [`cli/CHANGELOG.md`](./cli/CHANGELOG.md)). ```bash weknora auth login --host https://kb.example.com weknora kb list weknora link --kb my-knowledge-base # bind the current directory weknora doc upload notes.md weknora chat "summarise the design doc" ``` See [`cli/README.md`](./cli/README.md) for install + 5-minute quickstart and [`cli/AGENTS.md`](./cli/AGENTS.md) for the operational contract that AI agents (Claude Code, Cursor, Aider, …) can rely on. ## 🚀 Getting Started ### 🛠 Prerequisites - [Docker](https://www.docker.com/) & [Docker Compose](https://docs.docker.com/compose/) - [Git](https://git-scm.com/) ### 📦 Installation & Launch ```bash git clone https://github.com/Tencent/WeKnora.git cd WeKnora cp .env.example .env # Edit .env as needed, see comments in the file docker compose up -d # Start core services ``` Once started, visit **http://localhost** to get started. > To use a local Ollama model, run `ollama serve > /dev/null 2>&1 &` first. ### 🔧 Optional Services (Docker Compose Profiles) Add `--profile` flags to enable additional components. Multiple profiles can be combined: | Profile | Description | Command | |---------|-------------|---------| | _(default)_ | Core services | `docker compose up -d` | | `full` | All features | `docker compose --profile full up -d` | | `neo4j` | Knowledge Graph (Neo4j) | `docker compose --profile neo4j up -d` | | `minio` | Object Storage (MinIO) | `docker compose --profile minio up -d` | | `langfuse` | Tracing (Langfuse) | `docker compose --profile langfuse up -d` | Combine profiles: `docker compose --profile neo4j --profile minio up -d` Stop services: `docker compose down` ### 🌐 Service URLs | Service | URL | |---------|-----| | Web UI | `http://localhost` | | Backend API | `http://localhost:8080` | | Langfuse Tracing | `http://localhost:3000` | ## MCP Server Please refer to the [MCP Configuration Guide](./mcp-server/MCP_CONFIG.md) for the necessary setup. ## 🔌 Using WeChat Dialog Open Platform WeKnora serves as the core technology framework for the [WeChat Dialog Open Platform](https://chatbot.weixin.qq.com), providing a more convenient usage approach: - **Zero-code Deployment**: Simply upload knowledge to quickly deploy intelligent Q&A services within the WeChat ecosystem, achieving an "ask and answer" experience - **Efficient Question Management**: Support for categorized management of high-frequency questions, with rich data tools to ensure accurate, reliable, and easily maintainable answers - **WeChat Ecosystem Integration**: Through the WeChat Dialog Open Platform, WeKnora's intelligent Q&A capabilities can be seamlessly integrated into WeChat Official Accounts, Mini Programs, and other WeChat scenarios, enhancing user interaction experiences ## 📘 API Reference Troubleshooting FAQ: [Troubleshooting FAQ](./docs/QA.md) Detailed API documentation is available at: [API Docs](./docs/api/README.md) Product plans and upcoming features: [Roadmap](./docs/ROADMAP.md) ## 🧭 Developer Guide ### ⚡ Fast Development Mode (Recommended) If you need to frequently modify code, **you don't need to rebuild Docker images every time**! Use fast development mode: ```bash # Start infrastructure make dev-start # Start backend (new terminal) make dev-app # Start frontend (new terminal) make dev-frontend ``` **Development Advantages:** - ✅ Frontend modifications auto hot-reload (no restart needed) - ✅ Backend modifications quick restart (5-10 seconds, supports Air hot-reload) - ✅ No need to rebuild Docker images - ✅ Support IDE breakpoint debugging **Detailed Documentation:** [Development Environment Quick Start](./docs/开发指南.md) ## 🤝 Contributing Welcome to submit [Issues](https://github.com/Tencent/WeKnora/issues) or Pull Requests. **Process:** Fork → Create branch → Commit changes → Open PR **Standards:** Format code with `gofmt`, follow [Conventional Commits](https://www.conventionalcommits.org/) (`feat:` / `fix:` / `docs:` / `test:` / `refactor:`) ## 🔒 Security Notice **Important:** Starting from v0.1.3, WeKnora includes login authentication functionality to enhance system security. For production deployments, we strongly recommend: - Deploy WeKnora services in internal/private network environments rather than public internet - Avoid exposing the service directly to public networks to prevent potential information leakage - Configure proper firewall rules and access controls for your deployment environment - Regularly update to the latest version for security patches and improvements ## 👥 Contributors Thanks to these excellent contributors: [](https://github.com/Tencent/WeKnora/graphs/contributors) ## 📄 License This project is licensed under the [MIT License](./LICENSE). You are free to use, modify, and distribute the code with proper attribution. ## 📈 Project Statistics <a href="https://www.star-history.com/#Tencent/WeKnora&type=date&legend=top-left"> <picture> <source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=Tencent/WeKnora&type=date&theme=dark&legend=top-left" /> <source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=Tencent/WeKnora&type=date&legend=top-left" /> <img alt="Star History Chart" src="https://api.star-history.com/svg?repos=Tencent/WeKnora&type=date&legend=top-left" /> </picture> </a>
AI-Infra-Guard
<p align="center"> <h1 align="center"><img vertical-align="middle" width="400px" src="img/logo-full-new.png" alt="A.I.G"/></h1> </p> <p align="center"> <a href="https://tencent.github.io/AI-Infra-Guard/">📖 Documentation</a> | 🌐 <a href="./readme/README_ZH.md">🇨🇳 中文</a> · <a href="./readme/README_JA.md">🇯🇵 日本語</a> · <a href="./readme/README_ES.md">🇪🇸 Español</a> · <a href="./readme/README_DE.md">🇩🇪 Deutsch</a> · <a href="./readme/README_FR.md">🇫🇷 Français</a> · <a href="./readme/README_KR.md">🇰🇷 한국어</a> · <a href="./readme/README_PT.md">🇧🇷 Português</a> · <a href="./readme/README_RU.md">🇷🇺 Русский</a> </p> <p align="center"> <a href="https://github.com/tencent/AI-Infra-Guard/stargazers"> <img src="https://img.shields.io/github/stars/tencent/AI-Infra-Guard?style=social" alt="GitHub stars"> </a> <a href="https://github.com/Tencent/AI-Infra-Guard"> <img alt="GitHub downloads" src="https://img.shields.io/github/downloads/Tencent/AI-Infra-Guard/total"> </a> <a href="https://github.com/Tencent/AI-Infra-Guard"> <img alt="docker pulls" src="https://img.shields.io/docker/pulls/zhuquelab/aig-server.svg?color=gold"> </a> <a href="https://github.com/Tencent/AI-Infra-Guard"> <img alt="Release" src="https://img.shields.io/github/v/release/Tencent/AI-Infra-Guard?color=green"> </a> <a href="https://deepwiki.com/Tencent/AI-Infra-Guard"> <img src="https://deepwiki.com/badge.svg" alt="Ask DeepWiki"> </a> </p> <p align="center"> <a href="https://clawhub.ai/aigsec/edgeone-clawscan" target="_blank"> <img src="https://img.shields.io/badge/ClawHub-EdgeOne%20ClawScan-a870dc" alt="EdgeOne ClawScan"> </a> <a href="https://clawhub.ai/aigsec/edgeone-skill-scanner" target="_blank"> <img src="https://img.shields.io/badge/ClawHub-EdgeOne%20Skill%20Scanner-2ea44f" alt="EdgeOne Skill Scanner"> </a> <a href="https://clawhub.ai/aigsec/aig-scanner" target="_blank"> <img src="https://img.shields.io/badge/ClawHub-AIG%20Scanner-e6a817" alt="AIG Scanner"> </a> </p> <p align="center"> <a href="https://trendshift.io/repositories/13637" target="_blank"><picture><source media="(prefers-color-scheme: dark)" srcset="https://trendshift.io/api/badge/repositories/13637"><source media="(prefers-color-scheme: light)" srcset="https://trendshift.io/api/badge/repositories/13637"><img src="https://trendshift.io/api/badge/repositories/13637" alt="Tencent%2FAI-Infra-Guard | Trendshift" width="250" height="55"/></picture></a> <a href="https://www.blackhat.com/eu-25/arsenal/schedule/index.html#aigai-infra-guard-48381" target="_blank"><img src="img/blackhat.png" alt="Tencent%2FAI-Infra-Guard | blackhat" width="175" height="55"/></a> <a href="https://github.com/deepseek-ai/awesome-deepseek-integration" target="_blank"><img src="img/awesome-deepseek.png" alt="Tencent%2FAI-Infra-Guard | awesome-deepseek-integration" width="273" height="55"/></a> </p> <br> <p align="center"> <h2 align="center">🚀 AI Red Teaming Platform by Tencent Zhuque Lab</h2> </p> **A.I.G (AI-Infra-Guard)** integrates capabilities such as ClawScan(OpenClaw Security Scan), Agent Scan,AI infra vulnerability scan, MCP Server & Agent Skills scan, and Jailbreak Evaluation, aiming to provide users with the most comprehensive, intelligent, and user-friendly solution for AI security risk self-examination. <p> We are committed to making A.I.G(AI-Infra-Guard) the industry-leading AI red teaming platform. More stars help this project reach a wider audience, attracting more developers to contribute, which accelerates iteration and improvement. Your star is crucial to us! </p> <p align="center"> <a href="https://github.com/Tencent/AI-Infra-Guard"> <img src="https://img.shields.io/badge/⭐-Give%20us%20a%20Star-yellow?style=for-the-badge&logo=github" alt="Give us a Star"> </a> </p> <br> ## 🚀 What's New - **2026-06-08** · [v4.1.12](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.12) — Fingerprint library expanded: 39 new AI Web fingerprints added, 18 existing fingerprints enhanced. - **2026-06-04** · [v4.1.11](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.11) — New trusted-by endorsements: Wuhan University and Unicom Digital Tech. - **2026-05-28** · [v4.1.10](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.10) — Coverage expanded to 68 AI components (added junoclaw, lollms, sglang); 600+ new CVE rules; WebSocket agent provider support for Agent Scan. - **2026-05-21** · [v4.1.9](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.9) — Prompt Security: 26 new attack operators (20 single-turn + 6 multi-turn); scanning agents hardened against indirect prompt injection. - **2026-05-14** · [v4.1.8](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.8) — Coverage expanded to 64 AI components (6 new: InstructLab, LMDeploy, SuperAGI, Pipecat, Paperclip, QnABot); vuln database deduplicated and cleaned. - **2026-04-23** · [v4.1.6](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.6) — Coverage expanded to 58 AI components (added FastGPT, Upsonic); vuln database refreshed across 7 components. - **2026-04-23** · [v4.1.5](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.5) — Detects exposed AI agent config files (13 paths); manual update for jailbreak datasets and vuln databases. - **2026-04-17** · [v4.1.4](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.4) — HTTPS model endpoints with self-signed certificates now supported. - **2026-04-09** · [v4.1.3](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.3) — Coverage expanded to 55 AI components; added crewai, kubeai, lobehub. - **2026-04-03** · [v4.1.2](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.2) — Three new skills on ClawHub (`edgeone-clawscan`, `edgeone-skill-scanner`, `aig-scanner`) + manual task stop. - **2026-03-25** · [v4.1.1](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1.1) — ☠️ Detects LiteLLM supply chain attack (CRITICAL); added Blinko & New-API coverage. - **2026-03-23** · [v4.1](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.1) — OpenClaw vulnerability database expanded with 281 new CVE/GHSA entries. - **2026-03-10** · [v4.0](https://github.com/Tencent/AI-Infra-Guard/releases/tag/v4.0) — Launched EdgeOne ClawScan (OpenClaw Security Scan) and Agent-Scan framework. 👉 [CHANGELOG](./CHANGELOG.md) · 🩺 [Try EdgeOne ClawScan](https://matrix.tencent.com/clawscan) ## Table of Contents - [🚀 Quick Start](#-quick-start) - [✨ Features](#-features) - [🖼️ Showcase](#-showcase) - [📖 User Guide](#-user-guide) - [🔧 API Documentation](#-api-documentation) - [🏗️ Architecture Evolution](./docs/architecture_evolution.md) - [📝 Contribution Guide](#-contribution-guide) - [🛡️ About the Team](#️-about-the-team) - [🙏 Acknowledgements](#-acknowledgements) - [💬 Join the Community](#-join-the-community) - [📖 Citation](#-citation) - [📚 Papers](#-papers) - [⚖️ License & Attribution](#️-license--attribution) <br><br> ## 🚀 Quick Start ### Deployment with Docker | Docker | RAM | Disk Space | |:-------|:----|:----------| | 20.10 or higher | 4GB+ | 10GB+ | ```bash # This method pulls pre-built images from Docker Hub for a faster start git clone https://github.com/Tencent/AI-Infra-Guard.git cd AI-Infra-Guard # For Docker Compose V2+, replace 'docker-compose' with 'docker compose' docker-compose -f docker-compose.images.yml up -d ``` Once the service is running, you can access the A.I.G web interface at: `http://localhost:8088` <br> ### Use from OpenClaw You can also call A.I.G directly from OpenClaw chat via the `aig-scanner` skill. ```bash clawhub install aig-scanner ``` Then configure `AIG_BASE_URL` to point to your running A.I.G service. For more details, see the [`aig-scanner` README](./skills/aig-scanner/README.md). <details> <summary><strong>📦 More installation options</strong></summary> ### Other Installation Methods **Method 2: One-Click Install Script (Recommended)** ```bash # This method will automatically install Docker and launch A.I.G with one command curl https://raw.githubusercontent.com/Tencent/AI-Infra-Guard/refs/heads/main/docker.sh | bash ``` **Method 3: Build and run from source** ```bash git clone https://github.com/Tencent/AI-Infra-Guard.git cd AI-Infra-Guard # This method builds a Docker image from local source code and starts the service # (For Docker Compose V2+, replace 'docker-compose' with 'docker compose') docker-compose up -d ``` Note: The AI-Infra-Guard project is positioned as an AI red teaming platform for internal use by enterprises or individuals. It currently lacks an authentication mechanism and should not be deployed on public networks. For more information, see: [https://tencent.github.io/AI-Infra-Guard/?menu=getting-started](https://tencent.github.io/AI-Infra-Guard/?menu=getting-started) </details> ### Try the Online Pro Version Experience the Pro version with advanced features and improved performance. The Pro version requires an [invitation code](https://wj.qq.com/s2/25099467/25vn/) and is prioritized for contributors who have submitted issues, pull requests, or discussions, or actively help grow the community. Visit: [https://aigsec.ai/](https://aigsec.ai/). <br> <br> ## ✨ Features | Feature | More Info | |:--------|:------------| | **ClawScan(OpenClaw Security Scan)** | Supports one-click evaluation of OpenClaw security risks. It detects insecure configurations, Skill risks, CVE vulnerabilities, and privacy leakage. | | **Agent Scan** | This is an independent, multi-agent automated scanning framework. It is designed to evaluate the security of AI agent workflows. It seamlessly supports agents running across various platforms, including Dify and Coze. | | **MCP Server & Agent Skills scan** | It thoroughly detects 14 major categories of security risks. The detection applies to both MCP Servers and Agent Skills. It flexibly supports scanning from both source code and remote URLs. | | **AI infra vulnerability scan** | This scanner precisely identifies over 100 AI framework components. It covers more than 1600 known CVE vulnerabilities. Supported frameworks include Ollama, ComfyUI, vLLM, n8n, Triton Inference Server and more. | | **Jailbreak Evaluation** | It assesses prompt security risks using carefully curated datasets. The evaluation applies multiple attack methods to test robustness. It also provides detailed cross-model comparison capabilities. | <details> <summary><strong>💎 Additional Benefits</strong></summary> - 🖥️ **Modern Web Interface**: User-friendly UI with one-click scanning and real-time progress tracking - 🔌 **Complete API**: Full interface documentation and Swagger specifications for easy integration - 🤖 **Agent-Ready**: Plug-and-play agent skills on ClawHub — [EdgeOne ClawScan](https://clawhub.ai/aigsec/edgeone-clawscan), [EdgeOne Skill Scanner](https://clawhub.ai/aigsec/edgeone-skill-scanner), and [AIG Scanner](https://clawhub.ai/aigsec/aig-scanner) — seamlessly embed security scanning into any AI agent workflow - 🌐 **Multi-Language**: Chinese and English interfaces with localized documentation - 🐳 **Cross-Platform**: Linux, macOS, and Windows support with Docker-based deployment - 🆓 **Free & Open Source**: Completely free under the Apache 2.0 license </details> <br /> ## 🖼️ Showcase ### A.I.G Main Interface  ### Plugin Management  <br /> ## 🗺️ Quick Usage Guide > After deployment, open `http://localhost:8088` in your browser. ### AI Infrastructure Vulnerability Scan **What to enter as the target URL / IP?** The target is the **network address of a running AI service** you want to scan - not a GitHub URL or source code path. A.I.G connects to the live service and fingerprints it for known CVE vulnerabilities. | Scenario | Example target | |:---------|:--------------| | A locally running vLLM instance | `http://127.0.0.1:8000` | | An Ollama server on your LAN | `http://192.168.1.100:11434` | | A ComfyUI instance exposed internally | `http://10.0.0.5:8188` | | Multiple hosts (one per line) | `192.168.1.0/24` (CIDR), `10.0.0.1-10.0.0.20` (range) | **Step-by-step: Scan a local vLLM instance** 1. Start vLLM normally (e.g. `python -m vllm.entrypoints.api_server --model meta-llama/...`) 2. In the A.I.G web UI, click **"AI基础设施安全扫描 / AI Infra Scan"** 3. Enter `http://127.0.0.1:8000` (or the IP/port where vLLM is listening) 4. Click **Start Scan** - A.I.G will fingerprint the service and match it against 1600+ known CVEs 5. View the report: component version, matched vulnerabilities, severity, and remediation links > 💡 **Tip**: To scan the *nightly* build of vLLM specifically, just run that nightly build and point A.I.G at its address. The scanner detects the version automatically. ### MCP Server & Agent Skills Scan Enter either a **remote URL** (e.g. `https://github.com/user/mcp-server`) or **upload a local source archive** - no running instance required. ### Jailbreak Evaluation Configure the target LLM's API endpoint (base URL + API key) in **Settings → Model Config**, then select a dataset and start the evaluation. --- ## 📖 User Guide Visit our online documentation: [https://tencent.github.io/AI-Infra-Guard/](https://tencent.github.io/AI-Infra-Guard/) For more detailed FAQs and troubleshooting guides, visit our [documentation](https://tencent.github.io/AI-Infra-Guard/?menu=faq). <br /> <br> ## 🔧 API Documentation A.I.G provides a comprehensive set of task creation APIs that support AI infra scan, MCP Server Scan, and Jailbreak Evaluation capabilities. After the project is running, visit `http://localhost:8088/docs/index.html` to view the complete API documentation. For detailed API usage instructions, parameter descriptions, and complete example code, please refer to the [Complete API Documentation](./api.md). <br /> <br> ## 📝 Contribution Guide The extensible plugin framework serves as A.I.G's architectural cornerstone, inviting community innovation through Plugin and Feature contributions. ### Plugin Contribution Rules 1. **Fingerprint Rules**: Add new YAML fingerprint files to the `data/fingerprints/` directory. 2. **Vulnerability Rules**: Add new vulnerability scan rules to the `data/vuln/` directory. 3. **MCP Plugins**: Add new MCP security scan rules to the `data/mcp/` directory. 4. **Jailbreak Evaluation Datasets**: Add new Jailbreak evaluation datasets to the `data/eval` directory. Please refer to the existing rule formats, create new files, and submit them via a Pull Request. ### Other Ways to Contribute - 🐛 [Report a Bug](https://github.com/Tencent/AI-Infra-Guard/issues) - 💡 [Suggest a New Feature](https://github.com/Tencent/AI-Infra-Guard/issues) - ⭐ [Improve Documentation](https://github.com/Tencent/AI-Infra-Guard/pulls) <br /> <br /> ## 🛡️ About the Team This project is led and developed by **Tencent Zhuque Lab**, part of the Tencent Security Platform Department. Founded in 2019, [Tencent Zhuque Lab](https://matrix.tencent.com/) is a top-tier security research lab focused on real-world offensive and defensive research and frontier technology in the AI security space, covering large model security, AI agent security, AI-empowered security, and AI-generated content detection. The team has helped major vendors such as **NVIDIA, Google, and Microsoft**, as well as open-source communities like **OpenClaw, Linux, and Hugging Face**, fix a large number of high-risk vulnerabilities, and has been publicly acknowledged by them. We have released open-source AI security products including the AI Red Team Security Testing Platform **A.I.G (AI-Infra-Guard)** and the **Zhuque AI Detection Assistant**. Our research has been widely published at top international security and AI conferences such as **Black Hat, DEF CON, ICLR, CVPR, NeurIPS, and ACL**, and we have authored the book *"AI Security: Technology and Practice"*. ### 👥 Core Members & Contributions | Role | Member | Contribution | | --- | --- | --- | | Head of Tencent Security Platform Department | **Yong Yang** | Initiated A.I.G and proposed automated assessment of AI agent loss-of-control risks, guiding the platform's expansion from AI infrastructure vulnerability scanning to agent execution risk, tool misuse, and permission-boundary evaluation. | | Head of Tencent Zhuque Lab | **Xing Zheng** | Proposed the automated vulnerability-update and benchmark-alignment mechanism, helping AI Infra fingerprints, CVE/GHSA rules, and benchmarks iterate continuously. | | Project Lead | **Nicky** | Frontier security research, product planning, technical-route decisions, internal and external collaboration, and communications. | | Technical Lead | **Python** | Overall architecture design, core module development, and version iteration. | | Core Contributor | **Zona** | Frontend interaction, product experience, community operations, and user-feedback loop. | | Core Contributor | **Fyoung** | AI Infra vulnerability component fingerprint updates and Benchmark system construction. | | Core Contributor | **Robert** | LLM safety assessment and jailbreak-evaluation strategy operations. | | Core Contributor | **Zoe** | LLM safety assessment, jailbreak evaluation, and model-integration module development. | | Core Contributor | **Xiangfan** | Security capability development for Skill risks and agent loss-of-control scenarios. | | Contributor | **Ronin** | Participated in AI agent security scanning development. | | Contributor | **Rsin** | Participated in community operations and campaign communications. | <br /> ## 🙏 Acknowledgements ### 🎓 Academic Collaborations We thank our academic partners for their research contributions and technical support. #### <img src="img/北大未来网络重点实验室2.png" height="30" align="middle"/> <table> <tr> <td align="center" width="90"> <a href="#"> <img src="https://avatars.githubusercontent.com/u/0?v=4" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="#"> <sub><b>Prof. hui Li</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/TheBinKing"> <img src="https://avatars.githubusercontent.com/TheBinKing" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Bin Wang</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/KPGhat"> <img src="https://avatars.githubusercontent.com/KPGhat" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Zexin Liu</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/GioldDiorld"> <img src="https://avatars.githubusercontent.com/GioldDiorld" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Hao Yu</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/Jarvisni"> <img src="https://avatars.githubusercontent.com/Jarvisni" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Ao Yang</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/Zhengxi7"> <img src="https://avatars.githubusercontent.com/Zhengxi7" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Zhengxi Lin</b></sub> </a> </td> </tr> </table> #### <img src="img/复旦大学2.png" height="30" align="middle" style="vertical-align: middle;"/> <table> <tr> <td align="center" width="120"> <a href="https://yangzhemin.github.io/"> <img src="https://avatars.githubusercontent.com/yangzhemin" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Prof. Zhemin Yang</b></sub> </a> </td> <td align="center" width="100"> <a href="https://github.com/kangwei-zhong"> <img src="https://avatars.githubusercontent.com/kangwei-zhong" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Kangwei Zhong</b></sub> </a> </td> <td align="center" width="90"> <a href="https://github.com/MoonBirdLin"> <img src="https://avatars.githubusercontent.com/MoonBirdLin" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Jiapeng Lin</b></sub> </a> </td> <td align="center" width="90"> <a href="https://vanilla-tiramisu.github.io/"> <img src="https://avatars.githubusercontent.com/vanilla-tiramisu" width="70px;" style="border-radius: 50%;" alt=""/> </a> <br /> <a href="mailto:[email protected]"> <sub><b>Cheng Sheng</b></sub> </a> </td> </tr> </table> <br> ### 👥 Gratitude to Contributing Developers Thanks to all the developers who have contributed to the A.I.G project. <br /> <table border="0" cellspacing="0" cellpadding="0"> <tr> <td width="33%"><img src="img/keen_lab_logo.svg" alt="Keen Lab" height="85%"></td> <td width="33%"><img src="img/wechat_security.png" alt="WeChat Security" height="85%"></td> <td width="33%"><img src="img/fit_sec_logo.png" alt="Fit Security" height="85%"></td> </tr> </table> <a href="https://github.com/Tencent/AI-Infra-Guard/graphs/contributors"> <img src="https://contrib.rocks/image?repo=Tencent/AI-Infra-Guard" /> </a> <br> <br> ### 🤝 Appreciation for Our Users Thanks to the users from the following organizations and teams for using A.I.G and their valuable feedback. <br> <div align="center"> <img src="img/tencent.png" alt="Tencent" height="28px"> <img src="img/deepseek.png" alt="DeepSeek" height="38px"> <img src="img/antintl.svg" alt="Antintl" height="45px"> <img src="img/lenovo.png" alt="Lenovo" height="35px"> <img src="img/ICBC.jpg" alt="ICBC" height="40px"> <img src="img/vivo.png" alt="Vivo" height="30px"> <img src="img/oppo.png" alt="Oppo" height="30px"> <img src="img/haier.png" alt="Haier" height="30px"> <img src="img/abc.png" alt="Abc" height="40px"> <img src="img/JkOvmDOXpr.png" alt="招商银行" height="40px"> <img src="img/中国电信.png" alt="中国电信" height="40px"> <img src="img/bilibili.jpg" alt="Bilibili" height="38px"> <img src="img/qunar.png" alt="Qunar" height="35px"> <img src="img/蜜雪冰城.png" alt="蜜雪冰城" height="40px"> <img src="img/IDG.webp" alt="IDG" height="55px"> <img src="img/kingdee.png" alt="kingdee" height="40px"> <img src="img/unicom.png" alt="联通数科" height="40px"> <img src="img/changan.png" alt="长安汽车" height="40px"> </div> <div align="center"> <img src="img/清华大学.jpg" alt="清华大学" height="40px"> <img src="img/北京大学.png" alt="北京大学" height="40px"> <img src="img/fudan.png" alt="复旦大学" height="40px"> <img src="img/浙江大学.png" alt="浙江大学" height="40px"> <img src="img/南京大学.png" alt="南京大学" height="40px"> <img src="img/wuhan.png" alt="武汉大学" height="40px"> <img src="img/An-NajahNationalUniversity.png" alt="An-Najah National University" height="40px"> <img src="img/西安交通大学.png" alt="西安交通大学" height="40px"> <img src="img/huazhong.png" alt="华中科技大学" height="45px"> <img src="img/南开大学.jpg" alt="南开大学" height="45px"> <img src="img/四川大学.png" alt="四川大学" height="40px"> </div> <br> <br> ## 💬 Join the Community ### 🌐 Online Discussions - **GitHub Discussions**: [Join our community discussions](https://github.com/Tencent/AI-Infra-Guard/discussions) - **Issues & Bug Reports**: [Report issues or suggest features](https://github.com/Tencent/AI-Infra-Guard/issues) ### 📱 Discussion Community <table> <thead> <tr> <th>WeChat Group</th> <th>Discord <a href="https://discord.gg/U9dnPnyadZ">[link]</a></th> </tr> </thead> <tbody> <tr> <td><img src="img/wechatgroup.png" alt="WeChat Group" width="200"></td> <td><img src="img/discord.png" alt="discord" width="200"></td> </tr> </tbody> </table> ### 📧 Contact Us For collaboration inquiries or feedback, please contact us at: [[email protected]](mailto:[email protected]) ### 🔗 Recommended Security Tools If you are interested in code security, check out [A.S.E (AICGSecEval)](https://github.com/Tencent/AICGSecEval), the industry's first repository-level AI-generated code security evaluation framework open-sourced by the Tencent Wukong Code Security Team. <br> <br> ## 📖 Citation If you use A.I.G in your research, please cite: ```bibtex @misc{Tencent_AI-Infra-Guard_2025, author={{Tencent Zhuque Lab}}, title={{AI-Infra-Guard: A Comprehensive, Intelligent, and Easy-to-Use AI Red Teaming Platform}}, year={2025}, howpublished={GitHub repository}, url={https://github.com/Tencent/AI-Infra-Guard} } ``` <br> ## 📚 Papers 1. **"AI-Infra-Guard Technical Report"** — Technical report covering architecture design, scanning engine, and assessment methodology. [[pdf]](./AIG_Technical_Report.pdf) 2. **"AI-Infra-Guard: An AI Red Teaming Platform"** — Black Hat Europe 2025 Arsenal presentation showcasing A.I.G's capabilities and real-world use cases. [[pdf]](./Arsenal-BHEU2025-AI-Infra-Guard.pdf) 3. **"MCP Unchained: Compromising The AI Agent Ecosystem Via Its Universal Connector"** — Black Hat Europe 2025 talk revealing security risks in the MCP protocol within the AI agent ecosystem. [[pdf]](./BHEU-25-MCP-Unchained-Compromising-The-AI-Agent-Ecosystem-Via-Its-Universal-Connector.pdf) <details> <summary>Thanks to the research teams who have cited A.I.G in their academic work. Click to expand (19 papers)</summary> <br> 1. Chenning Li, Pan Hu, Justin Xu et al. **"ADR: An Agentic Detection System for Enterprise Agentic AI Security."** arXiv preprint arXiv:2605.17380 (2026). [[pdf]](http://arxiv.org/abs/2605.17380v1) 2. Zhaojiacheng Zhou. **"Proteus: A Self-Evolving Red Team for Agent Skill Ecosystems."** arXiv preprint arXiv:2605.11891 (2026). [[pdf]](http://arxiv.org/abs/2605.11891v1) 3. Hengkai Ye, Zhechang Zhang, Jinyuan Jia et al. **"TRUSTDESC: Preventing Tool Poisoning in LLM Applications via Trusted Description Generation."** arXiv preprint arXiv:2604.07536 (2026). [[pdf]](https://arxiv.org/abs/2604.07536) 4. Zenghao Duan, Yuxin Tian, Zhiyi Yin et al. **"SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement."** arXiv preprint arXiv:2604.04989 (2026). [[pdf]](https://arxiv.org/abs/2604.04989) 5. Yiheng Huang, Zhijia Zhao, Bihuan Chen et al. **"From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers."** arXiv preprint arXiv:2604.01905 (2026). [[pdf]](https://arxiv.org/abs/2604.01905) 6. Yi Ting Shen, Kentaroh Toyoda, Alex Leung. **"MCP-38: A Comprehensive Threat Taxonomy for Model Context Protocol Systems (v1.0)."** arXiv preprint arXiv:2603.18063 (2026). [[pdf]](https://arxiv.org/abs/2603.18063) 7. Yuepeng Hu, Yuqi Jia, Mengyuan Li et al. **"MalTool: Malicious Tool Attacks on LLM Agents."** arXiv preprint arXiv:2602.12194 (2026). [[pdf]](https://arxiv.org/abs/2602.12194) 8. Naen Xu, Jinghuai Zhang, Ping He et al. **"FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attacks."** arXiv preprint arXiv:2601.22485v1 (2026). [[pdf]](http://arxiv.org/abs/2601.22485v1) 9. Ruiqi Li, Zhiqiang Wang, Yunhao Yao et al. **"MCP-ITP: An Automated Framework for Implicit Tool Poisoning in MCP."** arXiv preprint arXiv:2601.07395v1 (2026). [[pdf]](http://arxiv.org/abs/2601.07395v1) 10. Jingxiao Yang, Ping He, Tianyu Du et al. **"HogVul: Black-box Adversarial Code Generation Framework Against LM-based Vulnerability Detectors."** arXiv preprint arXiv:2601.05587v1 (2026). [[pdf]](http://arxiv.org/abs/2601.05587v1) 11. Teofil Bodea, Masanori Misono, Julian Pritzi et al. **"Trusted AI Agents in the Cloud."** arXiv preprint arXiv:2512.05951v1 (2025). [[pdf]](http://arxiv.org/abs/2512.05951v1) 12. Yunyi Zhang, Shibo Cui, Baojun Liu et al. **"Beyond Jailbreak: Unveiling Risks in LLM Applications Arising from Blurred Capability Boundaries."** arXiv preprint arXiv:2511.17874v2 (2025). [[pdf]](http://arxiv.org/abs/2511.17874v2) 13. Bin Wang, Zexin Liu, Hao Yu et al. **"MCPGuard: Automatically Detecting Vulnerabilities in MCP Servers."** arXiv preprint arXiv:2510.23673v1 (2025). [[pdf]](http://arxiv.org/abs/2510.23673v1) 14. Weibo Zhao, Jiahao Liu, Bonan Ruan et al. **"When MCP Servers Attack: Taxonomy, Feasibility, and Mitigation."** arXiv preprint arXiv:2509.24272v1 (2025). [[pdf]](http://arxiv.org/abs/2509.24272v1) 15. Ping He, Changjiang Li, et al. **"Automatic Red Teaming LLM-based Agents with Model Context Protocol Tools."** arXiv preprint arXiv:2509.21011 (2025). [[pdf]](https://arxiv.org/abs/2509.21011) 16. Christian Coleman. **"Behavioral Detection Methods for Automated MCP Server Vulnerability Assessment."** (2025). [[pdf]](https://digitalcommons.odu.edu/cgi/viewcontent.cgi?article=1138&context=covacci-undergraduateresearch) 17. Yixuan Yang, Daoyuan Wu, Yufan Chen. **"MCPSecBench: A Systematic Security Benchmark and Playground for Testing Model Context Protocols."** arXiv preprint arXiv:2508.13220 (2025). [[pdf]](https://arxiv.org/abs/2508.13220) 18. Yongjian Guo, Puzhuo Liu, et al. **"Systematic Analysis of MCP Security."** arXiv preprint arXiv:2508.12538 (2025). [[pdf]](https://arxiv.org/abs/2508.12538) 19. Zexin Wang, Jingjing Li, et al. **"A Survey on AgentOps: Categorization, Challenges, and Future Directions."** arXiv preprint arXiv:2508.02121 (2025). [[pdf]](https://arxiv.org/abs/2508.02121) </details> 📧 If you have used A.I.G in your research or product, or if we have inadvertently missed your publication, we would love to hear from you! [Contact us here](#-join-the-community). <br> <br> ## ⚖️ License & Attribution This project is open-sourced under the **Apache License 2.0**. We warmly welcome and encourage community contributions, integrations, and derivative works, subject to the following attribution requirements: 1. **Retain notices**: You must retain the `LICENSE` and `NOTICE` files from the original project in any distribution. 2. **Product attribution**: If you integrate AI-Infra-Guard's core code, components, or scanning engine into your open-source project, commercial product, or internal platform, you must clearly state the following in your **product documentation, usage guide, or UI "About" page**: > "This project integrates [AI-Infra-Guard](https://github.com/Tencent/AI-Infra-Guard), open-sourced by Tencent Zhuque Lab." 3. **Academic & article citation**: If you use this tool in vulnerability analysis reports, security research articles, or academic papers, please explicitly mention "Tencent Zhuque Lab AI-Infra-Guard" and include a link to the repository. Repackaging this project as an original product without disclosing its origin is strictly prohibited. <div> [](https://star-history.com/#Tencent/AI-Infra-Guard&Date)
TNN
TNN is a high-performance, lightweight neural network inference framework developed by Tencent Youtu Lab and Guangying Lab. It serves as a uniform deep learning solution designed for cross-platform deployment on mobile, desktop, and server environments. Building upon the foundations of ncnn and Rapidnet, TNN delivers optimized performance specifically tailored for mobile devices while extending support for X86 and NVIDIA GPUs. Key features include robust cross-platform compatibility, advanced model compression capabilities, code proficiency, and high extensibility. The framework is already integrated into major Tencent applications such as Mobile QQ, Weishi, and Pitu, where it provides critical acceleration for various AI services including face detection, face alignment, hair segmentation, pose estimation, object detection, and Chinese optical character recognition. As a core acceleration infrastructure for Tencent Cloud AI, TNN supports the efficient implementation of diverse business scenarios. The project
TurboTransformers
## TurboTransformers: a fast and user-friendly runtime for transformer inference on CPU and GPU  <center>Make transformers serving fast by adding a turbo to your inference engine!</center> The WeChat AI open-sourced TurboTransformers with the following characteristics. 1. Supporting both Transformers Encoder and Decoder. 3. Supports Variable Length inputs. No time-consuming offline tuning is required. You can change batch size and sequence length at real-time. 3. Excellent CPU / GPU performance. 4. Perfect Usibility. TurboTransformers supports python and C++ APIs. 5. Smart Batching. Minimize zero-padding overhead for a batch of requests of different lengths. It can be used as a plugin for pytorch. Tthe end-to-end acceleration is obtained by adding a few lines of python code. TurboTransformers has been applied to multiple online BERT service scenarios in Tencent. For example, It brings 1.88x acceleration to the WeChat FAQ service, 2.11x acceleration to the public cloud sentiment analysis service, and 13.6x acceleration to the QQ recommendation system. Moreover, it has already been applied to build services such as Chitchating, Searching, and Recommendation. The following table is a comparison of TurboTransformers and related work. | Related Works | Performance | Need Preprocess | Variable Length | Usage | |------------------|---|---|---|---| | pytorch JIT (CPU) | Fast | Yes | No | Hard | | TensorRT (GPU) | Fast | Yes | No | Hard | | tf-Faster Transformers (GPU) | Fast | Yes | No | Hard | | ONNX-runtime (CPU/GPU) | Fast/Fast | No | Yes | Medium | | tensorflow-1.x (CPU/GPU) | Slow/Medium | Yes | No | Easy | | pytorch (CPU/GPU) | Medium/Medium | No | Yes | Easy | | **turbo-transformers (CPU/GPU)** | **Fastest/Fastest** | **No** | **Yes** | **Easy** | ### Supported Models We currently support the following transformer models. * [BERT](https://arxiv.org/abs/1810.04805) [[Python]](./example/python/bert_example.py) [[C++]](./example/python/bert_example.cpp) * [ALBERT](https://arxiv.org/abs/1909.11942) [[Python]](./example/python/albert_example.py) * [Roberta](https://arxiv.org/abs/1907.11692) [[Python]](./example/python/roberta_example.py) * [Transformer Decoder](https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/decoders/transformer.py) [[Python]](https://github.com/TurboNLP/Translate-Demo) * [GPT2](https://www.ceid.upatras.gr/webpages/faculty/zaro/teaching/alg-ds/PRESENTATIONS/PAPERS/2019-Radford-et-al_Language-Models-Are-Unsupervised-Multitask-%20Learners.pdf) [[Python]](./example/python/gpt2_example.py) ### Boost BERT Inference in 2 Lines of Python Code ```python import torch import transformers import turbo_transformers if __name__ == "__main__": turbo_transformers.set_num_threads(4) torch.set_num_threads(4) model_id = "bert-base-uncased" model = transformers.BertModel.from_pretrained(model_id) model.eval() cfg = model.config input_ids = torch.tensor( ([12166, 10699, 16752, 4454], [5342, 16471, 817, 16022]), dtype=torch.long) position_ids = torch.tensor(([1, 0, 0, 0], [1, 1, 1, 0]), dtype=torch.long) segment_ids = torch.tensor(([1, 1, 1, 0], [1, 0, 0, 0]), dtype=torch.long) torch.set_grad_enabled(False) torch_res = model( input_ids, position_ids=position_ids, token_type_ids=segment_ids ) # sequence_output, pooled_output, (hidden_states), (attentions) torch_seqence_output = torch_res[0][:, 0, :] tt_model = turbo_transformers.BertModel.from_torch(model) res = tt_model( input_ids, position_ids=position_ids, token_type_ids=segment_ids) # pooled_output, sequence_output tt_seqence_output = res[0] ``` ### Installation Note that the building scripts only apply to specific OS and software (Pytorch, OpenNMT, transformers, etc.) versions. Please adjust them according to your needs. #### CPU ``` git clone https://github.com/Tencent/TurboTransformers --recursive ``` 1. build docker images and containers on your machine. ``` sh tools/build_docker_cpu.sh # optional: If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows env BUILD_TYPE=dev sh tools/build_docker_cpu.sh docker run -it --rm --name=turbort -v $PWD:/workspace your_image_name /bin/bash ``` 2. Install turbo in docker Method 1: I want to unitest ``` cd /workspace sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=OFF # you can switch between Openblas and MKL by modifying this line in CMakeList.txt # set(BLAS_PROVIDER "mkl" CACHE STRING "Set the blas provider library, in [openblas, mkl, blis]") ``` Method 2: I do not want to unitest ``` cd /workspace mkdir -p build && cd build cmake .. -DWITH_GPU=OFF make -j 4 pip install `find . -name *whl` ``` 3. Run benchmark (optional) in docker, compare with pytorch, torch-JIT, onnxruntime ``` cd benchmark bash run_benchmark.sh ``` 4. Install conda packages in docker (optional) ``` sh tool/build_conda_package.sh # The conda package will be in /workspace/dist/*.tar.bz2 # When using turbo_transformers in other environments outside this container: conda install your_root_path/dist/*.tar.bz2 ``` *We also prepared a docker image containing CPU version of TurboTransformers, as well as other related works, i.e. onnxrt v1.2.0 and pytorch-jit on dockerhub* ``` docker pull thufeifeibear/turbo_transformers_cpu:latest ``` #### GPU ``` git clone https://github.com/Tencent/TurboTransformers --recursive ``` 1. build docker images and containers on your machine. ``` # You can modify the environment variables in the script to specify the cuda version and operating system version sh tools/build_docker_gpu.sh $PWD nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG # for example: nvidia-docker run --gpus all --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=turbo_gpu_env thufeifeibear:0.1.1-cuda9.0-ubuntu16.04-gpu-dev ``` 2. Install pip package in docker and unitest test ``` cd /workspace sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON ``` 3. Run benchmark (optional) in docker container, compare with pytorch ``` cd benchmark bash gpu_run_benchmark.sh ``` We also prepared a docker image containing GPU version of TurboTransformers. ``` docker pull thufeifeibear/turbo_transformers_gpu:latest ``` #### Using Tensor Core (FP16) [Tensor Core](https://developer.download.nvidia.cn/video/gputechconf/gtc/2019/presentation/s9926-tensor-core-performance-the-ultimate-guide.pdf) can accelerate computing on GPU. It is disabled by default in TurboTransformers. If you want to turn it on, before compiling code, set option WITH_MODULE_BENCHMAKR ON in CMakeLists.txt ``` option(WITH_TENSOR_CORE "Use Tensor core to accelerate" ON) ``` ### Usage TurboTransformers provides C++ / python API interfaces. We hope to do our best to adapt to a variety of online environments to reduce the difficulty of development for users. #### Pretrained Model Loading The first step in using turbo is to load a pre-trained model. We provide a way to load pytorch and tensorflow pre-trained models in [huggingface/transformers](https://github.com/huggingface). The specific conversion method is to use the corresponding script in ./tools to convert the pre-trained model into an npz format file, and turbo uses the C ++ or python interface to load the npz format model. In particular, we consider that most of the pre-trained models are in PyTorch format and used with python. We provide a shortcut for calling directly in python for the PyTorch saved model. <img width="700" height="150" src="./images/pretrainmodelload.jpg" alt="pretrained"> #### APIs ###### python APIs Refer to examples of supported models in [./example/python](./example/python "python"). [TurboNLP/Translate-Demo](https://github.com/TurboNLP/Translate-Demo "translate") shows a demo of applying TurboTransformer in Translation Task. Since the user of BERT acceleration always requires a customized post-processing process for the task, we provide an example of how to write a sequence classification application. ###### C++ APIs Refer to [./example/cpp](./example/cpp "C ++") for an example. Our example provides the GPU and two CPU multi-thread calling methods. One is to do one BERT inference using multiple threads; the other is to do multiple BERT inference, each of which using one thread. Users can link turbo-transformers to your code through add_subdirectory. #### Smart Batching (Minimize Zero-Padding Overhead in Batching) Usually, feeding a batch of requests of different lengths into a bert model for inference, zero-padding is required to make all the requests have the same length. For example, serving requests list of lengths (100, 10, 50), you need a preprocessing stage to pad them as lengths (100, 100, 100). In this way, 90% and 50% of the last two sequence's computation are wasted. As indicated in [Effective Transformer](https://github.com/bytedance/effective_transformer), it is not necessary to pad the input tensors. As an alternative, you just have to pad the batch-gemm operations inside multi-headed attentions, which accouts to a small propation of the entire BERT computation. Therefore most of gemm operations are processed without zero-padding. Turbo provides a model as `BertModelSmartBatch` including a smart batching technique. The example is presented in [./example/python/bert_smart_pad.py](./example/python/bert_smart_pad.py "smart_batching"). ## How to contribute new models [How to know hotspots of your code?](./docs/profiler.md) [How to add a new layer?](./turbo_transformers/layers/README.md) ## TODO Currently (June 2020), In the near future, we will add support for low-precision models (CPU int8, GPU FP16). **Looking forwards to your contribution!** ## License BSD 3-Clause License ## Known Issues 1. The results of Turbo Transformers may be different from the results of PyTorch after 2 digits behind the decimal point. The diff mainly comes from Bert Output Layer. We use an approximate GELU algorithm, which may be different from PyTorch. 2. Turbo and PyTorch share the same MKL. MKL of PyTorch 1.5.0 may slow in Turbo. Reasons need to be determined. Download PyTorch version to 1.1.0 will improve Turbo's Performance. 3. onnxruntime-cpu==1.4.0 and onnxruntime-gpu==1.3.0 can not work simultaneously. ## History 1. Janurary 2021 v0.6.0, TurboTransformers supports smart batching. 2. July 2020 v0.4.0, TurboTransformers used onnxruntime as cpu backend, supports GPT2. Anded a Quantized BERT. 3. July 2020 v0.3.1, TurboTransformers added support for ALbert, Roberta on CPU/GPU. 4. June 2020 v0.3.0, TurboTransformers added support for Transformer Decoder on CPU/GPU. 5. June 2020 v0.2.1, TurboTransformers added BLIS as a BLAS provider option. Better performance on AMD CPU. 6. April 2020 v0.0.1, TurboTransformers released, and achieved state-of-the-art BERT inference speed on CPU/GPU. ## Cite us Cite this paper, if you use TurboTransformers in your research publication. ``` @inproceedings{fang2021turbotransformers, title={TurboTransformers: an efficient GPU serving system for transformer models}, author={Fang, Jiarui and Yu, Yang and Zhao, Chengduo and Zhou, Jie}, booktitle={Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming}, pages={389--402}, year={2021} } ``` The artifacts of the paper can be found at branch `ppopp21_artifact_centos`. ## Contact us Although we recommend you post your problem with github issues, you can also join in our Turbo user group. 1. Scan this [QR code](./images/namecode.pdf "qrcode") and add our contactor as your WeChat friend. 2. QQ Group, Name: TurboTransformers, Number : 1109315167.
PatrickStar
## PatrickStar: Parallel Training of Large Language Models via a Chunk-based Memory Management  ### Recent Progress See [CHANGE_LOG.md](./CHANGE_LOG.md). ### Meeting PatrickStar Pre-Trained Models (PTM) are becoming the hotspot of both NLP research and industry application. However, the training of PTMs requires enormous hardware resources, making it only accessible to a small portion of people in the AI community. Now, **PatrickStar will make PTM training available to everyone!** Out-of-memory error (OOM) is the nightmare of every engineer training PTMs. We often have to introduce more GPUs to store the model params to prevent such errors. PatrickStar brings a better solution for such problem. With the **heterogeneous training** (DeepSpeed Zero Stage 3 also uses it), PatrickStar could fully use both the CPU and GPU memory so that you could use fewer GPUs to train larger models. ### System Design The idea of Patrick is like this. The non-model data (mainly activations) varies during training, but the current heterogeneous training solutions are **statically** splitting the model data to CPU and GPU. To better use the GPU, PatrickStar proposes a **dynamic** memory scheduling with the help of a chunk-based memory management module. The memory management of PatrickStar supports offloading everything but the current computing part of the model to the CPU to save GPU. In addition, chunk-based memory management is efficient for collective communication when scaling to multiple GPUs. See the paper and [this doc](./INSIDE.md) for the idea behind PatrickStar. ### Results In experiment, Patrickstar v0.4.3 is able to train a **18 Billion**(18B) param model with 8xTesla V100 GPU and 240GB GPU memory in WeChat datacenter node, whose network topology is like [this](./doc/yard_network_fabric.md). PatrickStar is over twice as large as DeepSpeed. And the performance of PatrickStar is better for models of the same size as well. The pstar is PatrickStar v0.4.3. The deeps indicates performance of DeepSpeed v0.4.3 using the official example [DeepSpeed example](https://github.com/microsoft/DeepSpeedExamples/blob/master/Megatron-LM-v1.1.5-ZeRO3/examples/ds_pretrain_gpt2-zero3.sh) zero3 stage with activation optimizations opening by default.  We also evaluated PatrickStar v0.4.3 on a single node of A100 SuperPod. It can train 68B model on 8xA100 with 1TB CPU memory, which is over 6x larger than DeepSpeed v0.5.7. Besides the model scale, PatrickStar is way more efficient than DeepSpeed. The benchmark scripts are in [here](./examples/benchmark).  Detailed benchmark results on the WeChat AI data center and NVIDIA SuperPod are posted on this [Google Doc](https://docs.google.com/spreadsheets/d/136CWc_jA_2zC4h1r-6dzD4PrOvp6aw6uCDchEyQv6sE/edit?usp=sharing). Scale PatrickStar to multiple machines (node) on SuperPod. We succeed in training a GPT3-175B on 32 GPU. As far as we know, it is the first work to run GPT3 on such a small GPU cluster. Microsoft used 10,000 V100 to pertain GPT3. Now you can finetune it or even pretrain your own one on 32 A100 GPU, amazing!  We've also trained the [CLUE-GPT2](https://huggingface.co/uer/gpt2-chinese-cluecorpussmall) model with PatrickStar, the loss and accuracy curve is shown below:  ### Installation ```bash pip install . ``` Note that PatrickStar requires gcc of version 7 or higher. You could also use NVIDIA NGC images, the following image is tested: ```bash docker pull nvcr.io/nvidia/pytorch:21.06-py3 ``` ### Usage PatrickStar is based on PyTorch, making it easy to migrate a pytorch project. Here is an example of PatrickStar: ```python from patrickstar.runtime import initialize_engine config = { "optimizer": { "type": "Adam", "params": { "lr": 0.001, "betas": (0.9, 0.999), "eps": 1e-6, "weight_decay": 0, "use_hybrid_adam": True, }, }, "fp16": { # loss scaler params "enabled": True, "loss_scale": 0, "initial_scale_power": 2 ** 3, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1, }, "default_chunk_size": 64 * 1024 * 1024, "release_after_init": True, "use_cpu_embedding": False, "client": { "mem_tracer": { "use_async_mem_monitor": args.with_async_mem_monitor, } }, } def model_func(): # MyModel is a derived class for torch.nn.Module return MyModel(...) model, optimizer = initialize_engine(model_func=model_func, local_rank=0, config=config) ... for data in dataloader: optimizer.zero_grad() loss = model(data) model.backward(loss) optimizer.step() ``` We use the same `config` format as [DeepSpeed configuration JSON](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters), which mainly includes params of optimizer, loss scaler, and some PatrickStar-specific configuration. For a detail explanation of the above example, please check the guide [here](./GUIDE.md) For more examples, please check [here](./examples). A quick-start benchmark script is [here](./examples/run_transformers.sh). It is executed with randomly generated data; therefore you do not need to prepare the real data. It also demonstrated all of the optimization techniques for patrickstar. For more optimization tricks running the benchmark see [Optimization Options](./doc/optimization_options.md). ### License BSD 3-Clause License ### Cite Us ``` @article{fang2021patrickstar, title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management}, author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie}, journal={arXiv preprint arXiv:2108.05818}, year={2021} } @article{fang2022parallel, title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management}, author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang}, journal={IEEE Transactions on Parallel and Distributed Systems}, volume={34}, number={1}, pages={304--315}, year={2022}, publisher={IEEE} } ``` ### Contact Us {jiaruifang, zilinzhu, josephyu}@tencent.com Powered by WeChat AI Team, Tencent NLP Oteam.
LightDiffusionFlow
<p float="left"> <img alt="" src="https://img.shields.io/badge/JavaScript-323330?style=for-the-badge&logo=javascript&logoColor=F7DF1E" /> <img alt="" src="https://img.shields.io/badge/Python-FFD43B?style=for-the-badge&logo=python&logoColor=blue" /> </p> # sd-webui-lightdiffusionflow [**English**](./README.md) | [**中文**](./README_CN.md) This extension is developed for AUTOMATIC1111's [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) that provides import/export options for parameters. "Stable Diffusion Web UI" hereafter referred to as "SD Web UI" * [**Plugin demonstration and other instructions**](https://fvkij7wuqx9.feishu.cn/docx/HgZndihraotmmzxFni7cFZISnvb) * [**LightFlow workflow community**](https://www.lightflow.ai/) * [**Discord**](https://discord.gg/CaD4mchHxW) * [**Twitter: @LightFlow_AI**](https://twitter.com/LightFlow_AI) ### Capabilities * Export/Import web UI parameters with a single file (images, inputs, sliders, checkboxes etc.) . * Support parsing png info from image and restoring parameters back to the web UI. * Supported extensions: - In theory, it can support any plugin. (Except for certain plugin images, as they require the corresponding elem_id to be provided.)  ### Install Use **Install from URL** option with this repo url. ### Requirements *None at all.* ### Usage * Export Parameters: In the SD Web UI, configure the desired options, and click the "Export" button to export a flow file that records the current parameters. * Import Parameters: In the SD Web UI, click the "FileBox", select the corresponding flow file, and import the parameters from the file. You can also directly drag and drop the flow file into the "FileBox" for importing. **Currently, the plugin supports SD WebUI versions v1.5 and above, and compatibility testing for earlier versions has not been conducted.** **If not due to compatibility issues with essential functionalities, it is strongly recommended to upgrade to version v1.6 or above before using this plugin!** ### Examples You can find several official examples in the example/ folder. If you want to try out more possibilities, please visit [**Our open-source community**](https://www.lightflow.ai/) for more public examples. ### Contributing If you have any comments, suggestions, or encounter issues with our project, please feel free to raise them through an issue, and we also welcome pull requests at any time! You are also more than welcomed to share your own LightDiffusionFlow on [**Our open-source community**](https://www.lightflow.ai/). ### Credits Licenses for borrowed code can be found in LICENSES/[**Licenses.md**](./LICENSES/Licenses.md) - stable-diffusion-webui-state - https://github.com/ilian6806/stable-diffusion-webui-state *Our team urgently needs a solution to easily share the Stable Diffusion Web UI settings, and Ilian Iliev's stable-diffusion-webui-state project has been a great help to us. Thank you, Ilian Iliev!* - Big thanks to [Hali](https://github.com/ThisHaliHali) for the inspiration, suggestions, and various forms of support during the development of this project. Much appreciated!
tencent-ml-images
# Tencent ML-Images This repository introduces the open-source project dubbed **Tencent ML-Images**, which publishes <!--- * **ML-Images**: the largest open-source multi-label image database, including 18,019,881 URLs to images, which are annotated with labels up to 11,166 categories--> * **ML-Images**: the largest open-source multi-label image database, including 17,609,752 training and 88,739 validation image URLs, which are annotated with up to 11,166 categories * **Resnet-101 model**: it is pre-trained on ML-Images, and achieves the top-1 accuracy 80.73% on ImageNet via transfer learning ## Updates * [2019/12/26] Our manuscript of this open-source project has been accepted to IEEE Access ([Journal](https://ieeexplore.ieee.org/document/8918053/authors#authors), [ArXiv](https://arxiv.org/abs/1901.01703)). It presents more details of the database, the loss function, the training algorithm, and more experimental results. * [2018/12/19] We simplify the procedure of downloading images. Please see [Download Images](#download-images). <!--- * [2018/12/22] We release one ArXiv manuscript at XXX, to demonstrate the details of our database, the loss function and training algorithm, as well as results. ---> # Contents * [Dependencies](#dependencies) * [Data](#data) * [Image Source](#image-source) * [Download Images](#download-images) * [Download Images from ImageNet](#download-images-from-imagenet) * [Download Images from Open Images](#download-images-from-open-images) * [Semantic Hierarchy](#semantic-hierarchy) * [Annotations](#annotations) * [Statistics](#statistics) * [Train](#train) * [Prepare the TFRecord File](#prepare-the-tfrecord-file) * [Pretrain on ML-Images](#pretrain-on-ml-images) * [Finetune on ImageNet](#finetune-on-imagenet) * [Checkpoints](#checkpoints) * [Single-Label Image Classification](#single-label-image-classification) * [Feature Extraction](#feature-extraction) * [Results](#results) * [Copyright](#copyright) * [Citation](#citation) # [Dependencies](#dependencies) * Linux * [Python 2.7](https://www.python.org/) * [Tensorflow >= 1.6.0](https://www.tensorflow.org/install/) # [Data](#data) [[back to top](#)] ### [Image Source](#image-source) [[back to top](#)] The image URLs of ML-Images are collected from [ImageNet](http://www.image-net.org/) and [Open Images](https://github.com/openimages/dataset). Specifically, * Part 1: From the whole database of ImageNet, we adopt 10,706,941 training and 50,000 validation image URLs, covering 10,032 categories. * Part 2: From Open Images, we adopt 6,902,811 training and 38,739 validation image URLs, covering 1,134 unique categories (note that some other categories are merged with their synonymous categories from ImageNet). Finally, ML-Images includes 17,609,752 training and 88,739 validation image URLs, covering 11,166 categories. <!--- The image URLs of ML-Images are collected from [ImageNet](http://www.image-net.org/) and [Open Images](https://github.com/openimages/dataset). Specifically, * Part 1: we adopt the set [ImageNet-11k](http://data.mxnet.io/models/imagenet-11k/). It is a subset of ImageNet, collected by [MXNet](http://mxnet.incubator.apache.org/). It includes 1,474,703 images and 11,221 categories. However, we find there are many abstract categories in visual domain, such as "event", "summer", etc. We think that the training images annotated with such abstract categories will not help (even harm) the visual representation learning. Thus, we abandon these categories. * Part 2: We filter the URLs of Open Images via a per-class criteria. Firstly, if one class occurs in less than 650 URLs, then it is removed. Besides, we also 1) remove some abstract categories as did above, and 2) merge some redundant categories with those in ImageNet. Then, if all annotated tags of one URL are removed, then this URL is abandoned. Consequently, 6,902,811 training URLs and 159,424 validation URLs are remained, covering 1,134 unique categories. ---> <!--- We then merge URLs from above two parts according to their categories. Specifically, we firstly all categories to their unique WordIDs defined in [WordNet](https://wordnet.princeton.edu/). According to the semantic topological structure of WordIDs, if two categories share the same WordID or are synonymous, then they are merged to a unique category, as well as their URLs. Finally, the number of remained URLs is 17,659,752, and the number of categories is 11,166. ---> <!--- Consequently, 8,385,050 training URLs and 159,424 validation URLs are remained, covering 2,039 categories. ---> ### [Download Images](#download-images) [[back to top](#)] Due to the copyright, we cannot provide the original images directly. However, one can obtain all images of our database using the following files: * train_image_id_from_imagenet.txt ([Link1](https://drive.google.com/file/d/1-7x4wPa764MJkjhhNj0PWPhgwMJOXziA/view?usp=sharing), [Link2](https://pan.baidu.com/s/1oUfIMCHj1wyz0ywuSn1iEQ)) * val_image_id_from_imagenet.txt ([Link1](https://drive.google.com/file/d/1-1x1vJFZGesz-5R2W8DLWHaVEbIPjuJs/view?usp=sharing), [Link2](https://pan.baidu.com/s/10prwZcHstYA8ppyXxbEbXA)) * train_urls_from_openimages.txt ([Link1](https://drive.google.com/file/d/1__HFVimF5yUwlyEjaUoSmBBfRQKJTYKW/view?usp=sharing), [Link2]( https://pan.baidu.com/s/1jjkaLu5JiHV6D0qyWXSxMA )) * val_urls_from_openimages.txt ([Link1](https://drive.google.com/file/d/1JkTcEEkB1zYI6NtAM-vXpsv7uDZ3glEz/view?usp=sharing), [Link2](https://pan.baidu.com/s/1F8mk58IGj9BP0-HSF-M9aw)) <!--- ##### Download images from ImageNet ---> #### [Download Images from ImageNet](#download-images-from-imagenet) We find that massive urls provided by ImageNet have expired (please check the file `List of all image URLs of Fall 2011 Release` at http://image-net.org/download-imageurls). Thus, here we provide the original image IDs of ImageNet used in our database. One can obtain the training/validation images of our database through the following steps: * Download the whole database of [ImageNet](http://image-net.org/download-images) * Extract the training/validation images using the image IDs in `train_image_id_from_imagenet.txt` and `val_image_id_from_imagenet.txt` The format of `train_image_id_from_imagenet.txt` is as follows: ``` ... n04310904/n04310904_8388.JPEG 2367:1 2172:1 1831:1 1054:1 1041:1 865:1 2:1 n11753700/n11753700_1897.JPEG 5725:1 5619:1 5191:1 5181:1 5173:1 5170:1 1042:1 865:1 2:1 ... ``` As shown above, one image corresponds to one row. The first term is the original image ID of ImageNet. The followed terms separated by space are the annotations. For example, "2367:1" indicates class 2367 and its confidence 1. Note that the class index starts from 0, and you can find the class name from the file [data/dictionary_and_semantic_hierarchy.txt](data/dictionary_and_semantic_hierarchy.txt). **NOTE**: We find that there are some repeated URLs in `List of all image URLs of Fall 2011 Release` of ImageNet, i.e., the image corresponding to one URL may be stored in multiple sub-folders with different image IDs. We manually check a few repeated images, and find the reason is that one image annotated with a child class may also be annotated with its parent class, then it is saved to two sub-folders with different image IDs. To the best of our knowledge, this point has never been claimed in ImageNet or any other place. If one want to use ImageNet, this point should be noticed. Due to that, there are also a few repeated images in our database, but our training is not significantly influenced. In future, we will update the database by removing the repeated images. #### [Download Images from Open Images](#download-images-from-open-images) <!--- * train_urls.txt ([link1](https://drive.google.com/open?id=1ExY0GpRWxGzDHAI-p44m-B0AB76NeLy7), [link2](https://pan.baidu.com/s/1cx6n6CYNqegKVq1O2YVCJg)) * val_urls.txt ([link1](https://drive.google.com/open?id=13SSar872e73UcshIW7IGbmvUGcFjHyxg), [link2](https://pan.baidu.com/s/1BfipStD2PY7MAMRoZa9ecg)) ---> The images from Open Images can be downloaded using URLs. The format of `train_urls_from_openimages.txt` is as follows: ``` ... https://c4.staticflickr.com/8/7239/6997334729_e5fb3938b1_o.jpg 3:1 5193:0.9 5851:0.9 9413:1 9416:1 https://c2.staticflickr.com/4/3035/3033882900_a9a4263c55_o.jpg 1053:0.8 1193:0.8 1379:0.8 ... ``` As shown above, one image corresponds to one row. The first term is the image URL. The followed terms separated by space are the annotations. For example, "5193:0.9" indicates class 5193 and its confidence 0.9. ##### Download Images using URLs We also provide the code to download images using URLs. As `train_urls_from_openimages.txt` is very large, here we provide a tiny file [train_urls_tiny.txt](data/train_urls_tiny.txt) to demonstrate the downloading procedure. ``` cd data ./download_urls_multithreading.sh ``` A sub-folder `data/images` will be generated to save the downloaded jpeg images, as well as a file `train_im_list_tiny.txt` to save the image list and the corresponding annotations. ### [Semantic Hierarchy](#semantic-hierarchy) [[back to top](#)] We build the semantic hiearchy of 11,166 categories, according to [WordNet](https://wordnet.princeton.edu/). The direct parent categories of each class can be found from the file [data/dictionary_and_semantic_hierarchy.txt](data/dictionary_and_semantic_hierarchy.txt). The whole semantic hierarchy includes 4 independent trees, of which the root nodes are `thing`, `matter`, `object, physical object` and `atmospheric phenomenon`, respectively. The length of the longest semantic path from root to leaf nodes is 16, and the average length is 7.47. ### [Annotations](#annotations) [[back to top](#)] Since the image URLs of ML-Images are collected from ImageNet and Open Images, the annotations of ML-Images are constructed based on the original annotations from ImageNet and Open Images. Note that the original annotations from Open Images are licensed by Google Inc. under [CC BY-4.0](https://creativecommons.org/licenses/by/4.0/). Specifically, we conduct the following steps to construct the new annotations of ML-Images. * For the 6,902,811 training URLs from Open Images, we remove the annotated tags that are out of the remained 1,134 categories. * According to the constructed [semantic hierarchy](data/dictionary_and_semantic_hierarchy.txt) of 11,166 categories, we augment the annotations of all URLs of ML-Images following the cateria that if one URL is annotated with category i, then all ancestor categories will also be annotated to this URL. * We train a ResNet-101 model based on the 6,902,811 training URLs from Open Images, with 1,134 outputs. Using this ResNet-101 model, we predict the tags from 1,134 categories for the 10,756,941 single-annotated image URLs from ImageNet. Consequently, we obtain a normalized co-occurrence matrix between 10,032 categories from ImageNet and 1,134 categories from Open Images. We can determine the strongly co-occurrenced pairs of categories. For example, category i and j are strongly co-occurrenced; then, if one image is annotated with category i, then category j should also be annotated. The annotations of all URLs in ML-Images are stored in `train_urls.txt` and `val_urls.txt`. <!--- (有关Open Images的部分,因为Annotations是适用CC BY-4.0(https://creativecommons.org/licenses/by/4.0/),所以如果有修改的话,是需要注明的。 License文件我会提,但您们rearme最好也要写,可以参考:https://wiki.creativecommons.org/wiki/Best_practices_for_attribution#This_is_a_good_attribution_for_material_you_modified_slightly 因为License文件我只提说:以下的文件可能已被修改,但readme里面就可能要写更详细点,像上面那个链接里的范例) ---> ### [Statistics](#statistics) [[back to top](#)] The main statistics of ML-Images are summarized in ML-Images. | # Train images | # Validation images | # Classes | # Trainable Classes | # Avg tags per image | # Avg images per class | | :-------------: |:--------------------:| :--------:| :-----------------: |:-------------------:| :---------------------:| | 17,609,752 | 88,739 | 11,166 | 10,505 | 8.72 | 13,843 | Note: *Trainable class* indicates the class that has over 100 train images. <br/> The number of images per class and the histogram of the number of annotations in training set are shown in the following figures. <img src="git_images/num_images_per_class.png" alt="GitHub" title="num images per class" width="430" height="240" /> <img src="git_images/hist_num_annotations.png" alt="GitHub" title="histogram of num annotations" width="400" height="240" /> # [Train](#train) [[back to top](#)] <!--- ### [Download Images using URLs](#download-images-using-urls) [[back to top](#)] ---> <!--- The full `train_urls.txt` is very large. Here we provide a tiny file [train_urls_tiny.txt](data/train_urls_tiny.txt) to demonstrate the downloading procedure. ``` cd data ./download_urls_multithreading.sh ``` A sub-folder `data/images` will be generated to save the downloaded jpeg images, as well as a file `train_im_list_tiny.txt` to save the image list and the corresponding annotations. ---> <!--- **Note**:Some URLs in [train_url.txt](https://pan.baidu.com/s/1cx6n6CYNqegKVq1O2YVCJg) have expired or may expire in future. If that, please provide us the missing URLs, we could provide the corresponding tfrecords. ---> <!--- #### [How to handle invalid URLs during downloading?](#How-to-handle-invalid-URLs-during-downloading) ##### For URLs from ImageNet The first 10,706,941 rows of `train_urls.txt` and the first 50,000 rows of `val_urls.txt` are URLs from ImageNet. A large proportion of these URLs have expired. However, the ImageNet website could provide the original images (see http://image-net.org/download), as well as the corresponse between each image ID and its original URL. Thus, we provide two novel files, that tell the image ID of each URL used in our database, including `train_urls_and_index_from_imagenet.txt` and `val_urls_and_index_from_imagenet.txt`. * train_urls_and_index_from_imagenet.txt ([link1](https://drive.google.com/open?id=1iK5j1zJ7SkitQ3ZIblYbUalAr5nFlngj), [link2](https://pan.baidu.com/s/145sGwH8Tv3RVwXZ95DuN4w)) * val_urls_and_index_from_imagenet.txt ([link1](https://drive.google.com/open?id=1ojVU0TIA3n9ytOW8p94IWbGD8QfXAfNj), [link2](https://pan.baidu.com/s/1p5sQrMUbfxiG94OjHj9-mQ)) ---> <!--- The format is as follows ``` ... n03874293_7679 http://image24.webshots.com/24/5/62/52/2807562520031003846EfpYGc_fs.jpg 2964:1 2944:1 2913:1 2896:1 2577:1 1833:1 1054:1 1041:1 865:1 2:1 n03580845_3376 http://i02.c.aliimg.com/img/offer/22/85/63/27/9/228563279 3618:1 3604:1 1835:1 1054:1 1041:1 865:1 2:1 ... ``` In each row, the first term is the image ID in ImageNet, while other terms are the corresponding URL and annotations. Then, two steps should be done to obtain the images used in ML-Images: * Download the original images of the whole database of ImageNet from (http://image-net.org/download), and the corresponding URL file is `List of all image URLs of Fall 2011 Release` (see http://image-net.org/download-imageurls) * Pick out the images used in ML-Images, accoording to `train_urls_and_index_from_imagenet.txt` and `val_urls_and_index_from_imagenet.txt`. ---> <!--- ##### For URLs from Open Images The last 6,902,811 rows of `train_urls.txt` and the last 38,739 rows of `val_urls.txt` are URLs from Open Images. Most of these URLs are valid, and you can directly download the images using the provided `download_urls_multithreading.sh`. ---> ### [Prepare the TFRecord File](#prepare-tfrecord) [[back to top](#)] Here we generate the tfrecords using the multithreading module. One should firstly split the file `train_im_list_tiny.txt` into multiple smaller files, and save them into the sub-folder `data/image_lists/`. ``` cd data ./tfrecord.sh ``` Multiple tfrecords (named like `x.tfrecords`) will saved to `data/tfrecords/`. ### [Pretrain on ML-Images](#pretrain-on-ml-images) [[back to top](#)] Before training, one should move the train and validation tfrecords to `data/ml-images/train` and `data/ml-images/val`, respectively. Then, ``` ./example/train.sh ``` **Note**: Here we only provide the training code in the single node single GPU framework, while our actual training on ML-Images is based on an internal distributed training framework (not released yet). One could modify the training code to the distributed framework following [distributed tensorFlow](https://www.tensorflow.org/deploy/distributed). ### [Finetune on ImageNet](#finetune-on-imagenet) [[back to top](#)] One should firstly download the ImageNet (ILSVRC2012) database, then prepare the tfrecord file using [tfrecord.sh](example/tfrecord.sh). Then, you can finetune the ResNet-101 model on ImageNet as follows, with the checkpoint pre-trained on ML-Images. ``` ./example/finetune.sh ``` ### [Checkpoints](#checkpoints) [[back to top](#)] * ckpt-resnet101-mlimages ([link1](https://drive.google.com/open?id=1FKkw2HD0jrCJKOM_kpyOvZ_m_YPA9tdV), [link2](https://pan.baidu.com/s/1166673BNWuIeWxD7lf6RNA)): pretrained on ML-Images * ckpt-resnet101-mlimages-imagenet ([link1](https://drive.google.com/open?id=1wIhRemoPxTw7uDz-TlwfYJsOR2usb2kg), [link2](https://pan.baidu.com/s/1UE7gavcVznYVA5NZ-GFAvg)): pretrained on ML-Images and finetuned on ImageNet (ILSVRC2012) Please download above two checkpoints and move them into the folder `checkpoints/`, if you want to extract features using them. ### [Single-Label Image Classification](#single-label-image-classification) Here we provide a demo for single-label image-classification, using the checkpoint `ckpt-resnet101-mlimages-imagenet` downloaded above. ``` ./example/image_classification.sh ``` The prediction will be saved to `label_pred.txt`. If one wants to recognize other images, `data/im_list_for_classification.txt` should be modified to include the path of these images. ### [Feature Extraction](#feature-extraction) [[back to top](#)] ``` ./example/extract_feature.sh ``` # [Results](#results) [[back to top](#)] The retults of different ResNet-101 checkpoints on the validation set of ImageNet (ILSVRC2012) are summarized in the following table. | Checkpoints | Train and finetune setting | <sub> Top-1 acc<br>on Val 224 </sub> | <sub> Top-5 acc<br>on Val 224 </sub> | <sub> Top-1 acc<br>on Val 299 </sub> | <sub> Top-5 acc<br>on Val 299 </sub> | :------------- |:--------------------| :--------:| :-----------------: |:------------------:| :-------------------:| <sub> [MSRA ResNet-101](https://github.com/KaimingHe/deep-residual-networks) </sub> | <sub> train on ImageNet </sub> | 76.4 | 92.9 | -- | -- | <sub> [Google ResNet-101 ckpt1](https://arxiv.org/abs/1707.02968) </sub> | <sub> train on ImageNet, 299 x 299 </sub> | -- | -- | 77.5 | 93.9 | <sub> Our ResNet-101 ckpt1 </sub> | <sub> train on ImageNet </sub> | 77.8 | 93.9 | 79.0 | 94.5 | <sub> [Google ResNet-101 ckpt2](https://arxiv.org/abs/1707.02968) </sub> | <sub> Pretrain on JFT-300M, finetune on ImageNet, 299 x 299 </sub> | -- | -- | 79.2 | 94.7 | <sub> Our ResNet-101 ckpt2 </sub> | <sub> Pretrain on ML-Images, finetune on ImageNet </sub> | **78.8** | **94.5** | 79.5 | 94.9 | <sub> Our ResNet-101 ckpt3 </sub> | <sub> Pretrain on ML-Images, finetune on ImageNet 224 to 299 </sub> | 78.3 | 94.2 | **80.73** | **95.5** | <sub> Our ResNet-101 ckpt4 </sub> | <sub> Pretrain on ML-Images, finetune on ImageNet 299 x 299 </sub> | 75.8 | 92.7 | 79.6 | 94.6 | Note: * if not specified, the image size in training/finetuning is 224 x 224. * *finetune on ImageNet from 224 to 299* means that the image size in early epochs of finetuning is 224 x 224, then 299 x 299 in late epochs. * *Top-1 acc on Val 224* indicates the top-1 accuracy on 224 x 224 validation images. # [Copyright](#copyright) [[back to top](#)] The annotations of images are licensed by Tencent under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license. The contents of this repository, including the codes, documents and checkpoints, are released under an [BSD 3-Clause](https://opensource.org/licenses/BSD-3-Clause) license. Please refer to [LICENSE](LICENSE) for more details. If there is any concern about the copyright of any image used in this project, please [email us](mailto:[email protected]). # [Citation](#citation) [[back to top](#)] If any content of this project is utilized in your work (such as data, checkpoint, code, or the proposed loss or training algorithm), please cite the following manuscript. ``` @article{tencent-ml-images-2019, title={Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning}, author={Wu, Baoyuan and Chen, Weidong and Fan, Yanbo and Zhang, Yong and Hou, Jinlong and Liu, Jie and Zhang, Tong}, journal={IEEE Access}, volume={7}, year={2019} } ```
PocketFlow
# PocketFlow PocketFlow is an open-source framework for compressing and accelerating deep learning models with minimal human effort. Deep learning is widely used in various areas, such as computer vision, speech recognition, and natural language translation. However, deep learning models are often computational expensive, which limits further applications on mobile devices with limited computational resources. PocketFlow aims at providing an easy-to-use toolkit for developers to improve the inference efficiency with little or no performance degradation. Developers only needs to specify the desired compression and/or acceleration ratios and then PocketFlow will automatically choose proper hyper-parameters to generate a highly efficient compressed model for deployment. PocketFlow was originally developed by researchers and engineers working on machine learning team within Tencent AI Lab for the purposes of compacting deep neural networks with industrial applications. For full documentation, please refer to [PocketFlow's GitHub Pages](https://pocketflow.github.io/). To start with, you may be interested in the [installation guide](https://pocketflow.github.io/installation/) and the [tutorial](https://pocketflow.github.io/tutorial/) on how to train a compressed model and deploy it on mobile devices. For general discussions about PocketFlow development and directions please refer to [PocketFlow Google Group](https://groups.google.com/forum/#!forum/pocketflow). If you need a general help, please direct to [Stack Overflow](https://stackoverflow.com/). You can report issues, bug reports, and feature requests on [GitHub Issue Page](https://github.com/Tencent/PocketFlow/issues). **News: we have created a QQ group (ID: 827277965) for technical discussions. Welcome to join us!** <img src="docs/qr_code.jpg" alt="qr_code" width="256"/> ## Framework The proposed framework mainly consists of two categories of algorithm components, *i.e.* learners and hyper-parameter optimizers, as depicted in the figure below. Given an uncompressed original model, the learner module generates a candidate compressed model using some randomly chosen hyper-parameter combination. The candidate model's accuracy and computation efficiency is then evaluated and used by hyper-parameter optimizer module as the feedback signal to determine the next hyper-parameter combination to be explored by the learner module. After a few iterations, the best one of all the candidate models is output as the final compressed model.  ## Learners A learner refers to some model compression algorithm augmented with several training techniques as shown in the figure above. Below is a list of model compression algorithms supported in PocketFlow: | Name | Description | |:-----|:------------| | `ChannelPrunedLearner` | channel pruning with LASSO-based channel selection (He et al., 2017) | | `DisChnPrunedLearner` | discrimination-aware channel pruning (Zhuang et al., 2018) | | `WeightSparseLearner` | weight sparsification with dynamic pruning schedule (Zhu & Gupta, 2017) | | `UniformQuantLearner` | weight quantization with uniform reconstruction levels (Jacob et al., 2018) | | `UniformQuantTFLearner` | weight quantization with uniform reconstruction levels and TensorFlow APIs | | `NonUniformQuantLearner` | weight quantization with non-uniform reconstruction levels (Han et al., 2016) | All the above model compression algorithms can trained with fast fine-tuning, which is to directly derive a compressed model from the original one by applying either pruning masks or quantization functions. The resulting model can be fine-tuned with a few iterations to recover the accuracy to some extent. Alternatively, the compressed model can be re-trained with the full training data, which leads to higher accuracy but usually takes longer to complete. To further reduce the compressed model's performance degradation, we adopt network distillation to augment its training process with an extra loss term, using the original uncompressed model's outputs as soft labels. Additionally, multi-GPU distributed training is enabled for all learners to speed-up the time-consuming training process. ## Hyper-parameter Optimizers For model compression algorithms, there are several hyper-parameters that may have a large impact on the final compressed model's performance. It can be quite difficult to manually determine proper values for these hyper-parameters, especially for developers that are not very familiar with algorithm details. Recently, several AutoML systems, *e.g.* [Cloud AutoML](https://cloud.google.com/automl/) from Google, have been developed to train high-quality machine learning models with minimal human effort. Particularly, the AMC algorithm (He et al., 2018) presents promising results for adopting reinforcement learning for automated model compression with channel pruning and fine-grained pruning. In PocketFlow, we introduce the hyper-parameter optimizer module to iteratively search for the optimal hyper-parameter setting. We provide several implementations of hyper-parameter optimizer, based on models including Gaussian Processes (GP, Mockus, 1975), Tree-structured Parzen Estimator (TPE, Bergstra et al., 2013), and Deterministic Deep Policy Gradients (DDPG, Lillicrap et al., 2016). The hyper-parameter setting is optimized through an iterative process. In each iteration, the hyper-parameter optimizer chooses a combination of hyper-parameter values, and the learner generates a candidate model with fast fast-tuning. The candidate model is evaluated to calculate the reward of the current hyper-parameter setting. After that, the hyper-parameter optimizer updates its model to improve its estimation on the hyper-parameter space. Finally, when the best candidate model (and corresponding hyper-parameter setting) is selected after some iterations, this model can be re-trained with full data to further reduce the performance loss. ## Performance In this section, we present some of our results for applying various model compression methods for ResNet and MobileNet models on the ImageNet classification task, including channel pruning, weight sparsification, and uniform quantization. For complete evaluation results, please refer to [here](https://pocketflow.github.io/performance/). ### Channel Pruning We adopt the DDPG algorithm as the RL agent to find the optimal layer-wise pruning ratios, and use group fine-tuning to further improve the compressed model's accuracy: | Model | FLOPs | Uniform | RL-based | RL-based + Group Fine-tuning | |:------------:|:-----:|:-------:|:-------------:|:----------------------------:| | MobileNet-v1 | 50% | 66.5% | 67.8% (+1.3%) | 67.9% (+1.4%) | | MobileNet-v1 | 40% | 66.2% | 66.9% (+0.7%) | 67.0% (+0.8%) | | MobileNet-v1 | 30% | 64.4% | 64.5% (+0.1%) | 64.8% (+0.4%) | | Mobilenet-v1 | 20% | 61.4% | 61.4% (+0.0%) | 62.2% (+0.8%) | ### Weight Sparsification Comparing with the original algorithm (Zhu & Gupta, 2017) which uses the same sparsity for all layers, we incorporate the DDPG algorithm to iteratively search for the optimal sparsity of each layer, which leads to the increased accuracy: | Model | Sparsity | (Zhu & Gupta, 2017) | RL-based | |:------------:|:--------:|:-------------------:|:-----------------------:| | MobileNet-v1 | 50% | 69.5% | 70.5% (+1.0%) | | MobileNet-v1 | 75% | 67.7% | 68.5% (+0.8%) | | MobileNet-v1 | 90% | 61.8% | 63.4% (+1.6%) | | MobileNet-v1 | 95% | 53.6% | 56.8% (+3.2%) | ### Uniform Quantization We show that models with 32-bit floating-point number weights can be safely quantized into their 8-bit counterpart without accuracy loss (sometimes even better!). The resulting model can be deployed on mobile devices for faster inference (Device: XiaoMi 8 with a Snapdragon 845 CPU): | Model | Acc. (32-bit) | Acc. (8-bit) | Time (32-bit) | Time (8-bit) | |:------------:|:-------------:|:---------------:|:-------------:|:-------------:| | MobileNet-v1 | 70.89% | 71.29% (+0.40%) | 124.53 | 56.12 (2.22x) | | MobileNet-v2 | 71.84% | 72.26% (+0.42%) | 120.59 | 49.04 (2.46x) | * All the reported time are in milliseconds. ## Citation Please cite PocketFlow in your publications if it helps your research: ``` bibtex @incollection{wu2018pocketflow, author = {Jiaxiang Wu and Yao Zhang and Haoli Bai and Huasong Zhong and Jinlong Hou and Wei Liu and Junzhou Huang}, title = {PocketFlow: An Automated Framework for Compressing and Accelerating Deep Neural Networks}, booktitle = {Advances in Neural Information Processing Systems (NIPS), Workshop on Compact Deep Neural Networks with Industrial Applications}, year = {2018}, } ``` ## Reference * [**Bergstra et al., 2013**] J. Bergstra, D. Yamins, and D. D. Cox. *Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures*. In International Conference on Machine Learning (ICML), pages 115-123, Jun 2013. * [**Han et al., 2016**] Song Han, Huizi Mao, and William J. Dally. *Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding*. In International Conference on Learning Representations (ICLR), 2016. * [**He et al., 2017**] Yihui He, Xiangyu Zhang, and Jian Sun. *Channel Pruning for Accelerating Very Deep Neural Networks*. In IEEE International Conference on Computer Vision (ICCV), pages 1389-1397, 2017. * [**He et al., 2018**] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. *AMC: AutoML for Model Compression and Acceleration on Mobile Devices*. In European Conference on Computer Vision (ECCV), pages 784-800, 2018. * [**Jacob et al., 2018**] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. *Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference*. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2704-2713, 2018. * [**Lillicrap et al., 2016**] Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. *Continuous Control with Deep Reinforcement Learning*. In International Conference on Learning Representations (ICLR), 2016. * [**Mockus, 1975**] J. Mockus. *On Bayesian Methods for Seeking the Extremum*. In Optimization Techniques IFIP Technical Conference, pages 400-404, 1975. * [**Zhu & Gupta, 2017**] Michael Zhu and Suyog Gupta. *To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression*. CoRR, abs/1710.01878, 2017. * [**Zhuang et al., 2018**] Zhuangwei Zhuang, Mingkui Tan, Bohan Zhuang, Jing Liu, Jiezhang Cao, Qingyao Wu, Junzhou Huang, and Jinhui Zhu. *Discrimination-aware Channel Pruning for Deep Neural Networks*. In Annual Conference on Neural Information Processing Systems (NIPS), 2018. ### Contributing If you are interested in contributing, check out the [CONTRIBUTING.md](https://github.com/Tencent/PocketFlow/blob/master/CONTRIBUTING.md), also join our [Tencent OpenSource Plan](https://opensource.tencent.com/contribution).